

0.为什么智能体需要“记忆”?
智能体的运行需要记忆(Memory)、规划(Planning)、工具(Tools)和行动(Action)协同完成,其概览如图 1所示。
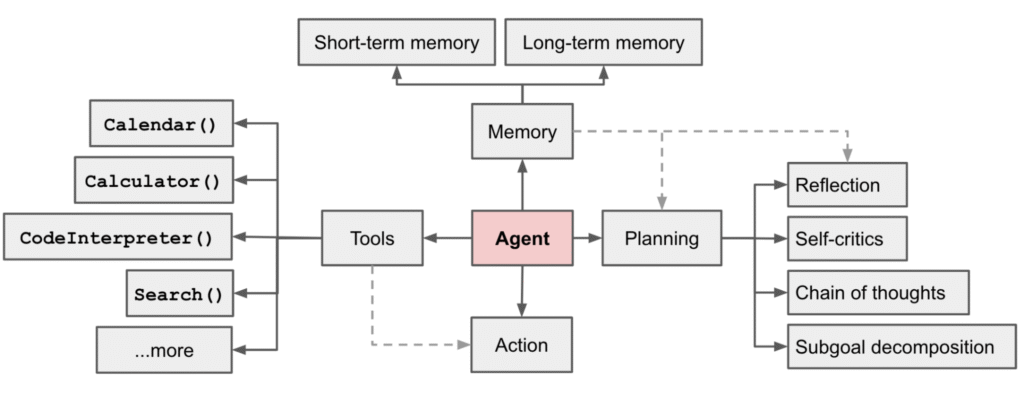
图 1 智能体概览
在大多数对话式或自主式智能体系统中,记忆并非可有可无的附加功能,而是构成智能体可用性和效率的关键能力。其主要原因包括以下四点:
(1)连续性
智能体必须能够跨对话轮次理解上下文。例如,在同一对话中,当用户先后表示“我不喝含糖饮料”和“我也不喜欢碳酸饮料”时,智能体应能识别出用户既不饮用含糖饮料也不偏好碳酸饮料。
(2)个性化
能否把握用户的偏好(例如口味、风格、行话/术语等)是区分“优质回答”与“劣质回答”的关键。缺乏记忆功能将无法实现持续的个性化服务,反复要求用户重述其偏好的交互体验,想必没有人愿意忍受。
(3)成本与稳定性
为了保持上下文信息,简单地将对话拼接起来是一种实现方法,但这种方法不仅成本高昂(因为要使用大量的token),而且随着对话的持续,容易导致早期的关键信息被遗忘。即一味扩大上下文窗口将导致调用成本上升、响应时间延长,并且会引入更多的“信息噪声”。以记忆为核心进行取舍(保留关键信息、舍弃冗余内容)能够显著降低这些成本,并提供更为稳定和可靠的上下文信息。
(4)工程可观测与控制
记忆使得“信息的来源和使用方式”变得可追溯、可核查;通过指标和日志可以验证链路质量、排查错误召回,满足线下优化与合规性要求。
简而言之,“记忆=更低的成本、更个性化的体验、更可控的上下文管理”。本篇提供了一个包含短期记忆(STM,Short-Term Memory)和长期记忆(LTM,Long-Term Memory)两个部分的最小化实现参考方案。
1.设计总览与数据流
前文已经阐述了记忆对于智能体的重要性。本文将从工程实践的角度,提供一套最小化但功能完备的实现方案,并通过数据流图清晰地展示核心组件之间的相互作用。本文示例的设计选择遵循以下三个原则:
1)维持上下文的体积:短期记忆采用“滚动窗口 + 词数限制 + 精简摘要”的策略,避免无限制的累积;
2)确保关键信息可回忆:长期记忆通过“向量化 + Top-K 检索”实现,仅在信息“具有保存价值”时进行记录;
3)易于集成和演示:不依赖外部向量数据库和附加服务,所有组件可以在一个文件中运行,便于学习和快速验证。
在不同的智能系统中,短期记忆与长期记忆的保持策略会有所不同。本示例这两种记忆的策略具体如下:
1)短期记忆:维持最近的对话片段(例如近6轮对话),在达到词数预算(近似token数)上限时,生成极简摘要(采用不使用大语言模型的方式实现,无需额外依赖),并删除一半的旧消息,以保持上下文的体积稳定。
2)长期记忆:将需要长期保留的信息(例如用户偏好等)进行向量化处理,并存储于内存向量数据库中。
智能体使用短期记忆与长期记忆的方式则是在回答问题前,先以“当前问题 + STM摘要”对LTM做相似检索,再把Top-K命中片段与“当前问题 + STM 摘要 + 最近对话原文”一并注入提示词。其完整数据流如图 2所示。
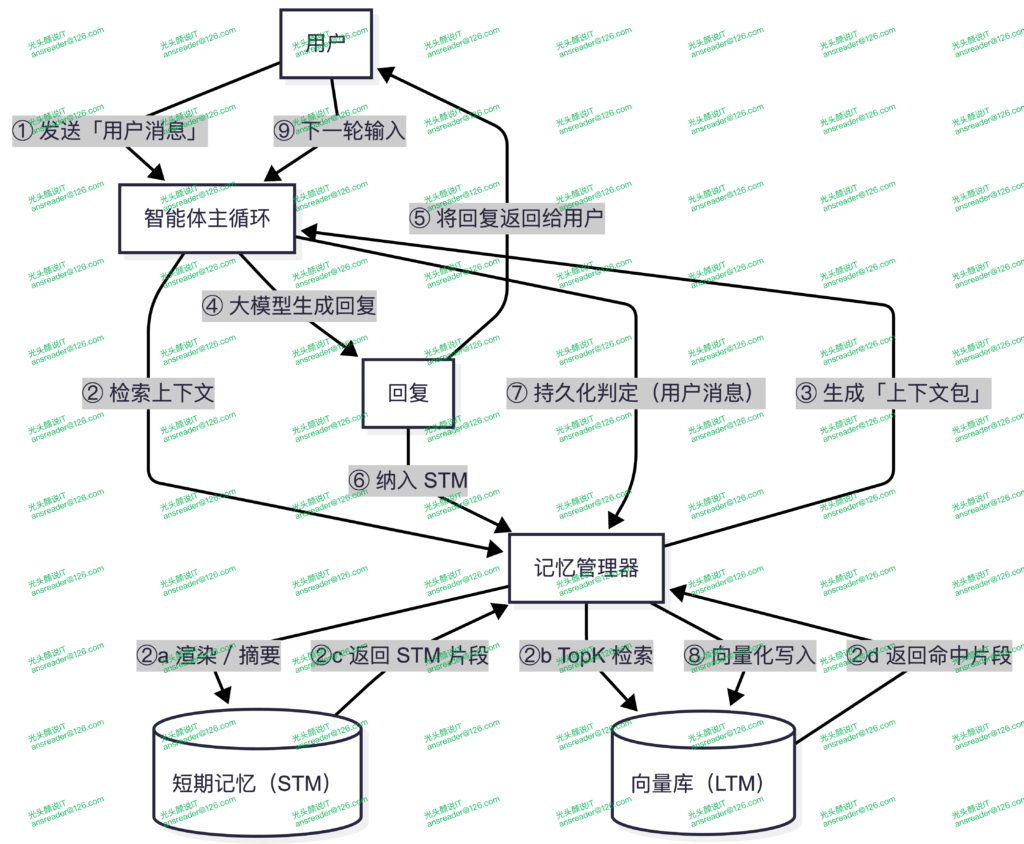
图 2 包含记忆的数据流
2.短期记忆(STM):滚动窗口 + 词数预算 + 极简摘要
短期记忆的目标是在尽量不丢失上下文关键线索前提下,稳定控制传给大语言模型的上下文体积。其核心策略是仅保留最近对话信息。如果最近对话原文体积依然过大,则进一步对这些对话原文的前半部分进行摘要并保存,然后移除前半部分的对话原文。
保留最近对话信息的策略按以下三步实施:
1)限制对话回合数上限,即仅保留最大设定的对话回合数,当对话回合数超出该上限时,则将最大对话回合数之前的原文直接删除,避免上下文持续累积增长。
2)比较当前保留的最近对话回合原文的体积与词数预算(近似token数),如原文体积超出词数预算,则触发对前一半的消息进行极简摘要,并在摘要后删除这前一半消息。
3)如果在第2)步中触发了极简摘要,则对前一半消息中的每条消息均抽第一句拼接形成摘要。这个处理方式没有外部依赖、足够稳定,但有效性可能不足。在落地项目中需要高质量的摘要,因而有必要替换成使用大语言模型生成摘要。
短期记忆机制由Message和ShortTermMemory两个类具体实现。
Message类是一个数据类,其每个实例保存一条对话消息,它记录了消息角色、消息内容及消息记录时间。
@dataclass
class Message:
"""对话消息的轻量结构。role 取值:'user'/'assistant'/'system'。"""
role: str
content: str
ts: float = field(default_factory=now_ts)ShortTermMemory类通过属性turns保存多个回合的对话消息,提供append()方法向turns追加一条新对话,并在该方法中检查总的对话回合数,在超出限制回合数时对消息列表进行裁剪,并在最后调用_trim_if_needed()以根据词数限制对短期记忆进行进一步的裁剪。
_naive_summary()方法用于生成极简摘要,它由_trim_if_needed()方法调用,以便在根据词数对对话消息进行裁剪之前生成摘要并保存该摘要。
render()方法根据需求组合摘要及最近对话消息作为短期记忆内容提供给智能体使用。
此外,ShortTermMemory类还提供了一个clear()方法,它用于清空当前的短期记忆。
class ShortTermMemory:
"""
目标:始终保持“够用”的最近上下文,且总体大小受控。
做法:
- 限制最大回合数(max_turns);
- 用“词数预算”(max_words)估算上下文体积,若超限→生成极简“摘要”,并裁掉一半旧消息。
说明:
- 这里的“摘要”是启发式实现(取“首句”拼接),为了示例尽量不引入 LLM。
- 如果你追求摘要质量,可把 _naive_summary 改为“调用 LLM 生成摘要”。
"""
def __init__(self, max_turns: int = 12, max_words: int = 800):
self.turns: deque[Message] = deque()
self.max_turns = max_turns
self.max_words = max_words
self._summary: Optional[str] = None
def append(self, role: str, content: str):
"""追加一条消息到短期记忆,并在必要时触发裁剪/摘要。"""
self.turns.append(Message(role=role, content=content))
# 先按“回合数”粗裁
while len(self.turns) > self.max_turns:
self.turns.popleft()
# 再按“词数预算”细裁
self._trim_if_needed()
def _trim_if_needed(self):
"""若当前上下文超出词数预算:先摘要“将被丢弃的旧消息”,再删除它们。"""
text = self.render(include_summary=False)
if len(tokenize(text)) > self.max_words:
# 先锁定要丢弃的旧半区,并对其做摘要,避免信息完全丢失
half = len(self.turns) // 2
to_discard = list(self.turns)[:half]
self._summary = self._naive_summary(to_discard)
# 丢弃一半最早消息,保留“近期上下文”
for _ in range(half):
self.turns.popleft()
def _naive_summary(self, msgs: Optional[List[Message]] = None) -> str:
"""
极简摘要策略:
- 若传入 msgs,则对 msgs 全量抽取“第一句”拼摘要;
- 否则取 self.turns 的前 N 条(≤6),抽取“第一句”拼摘要。
- 这样做能在完全不依赖 LLM 的情况下,给上下文一个“压缩版线索”。
"""
corpus = msgs if msgs is not None else list(self.turns)[: min(6, len(self.turns))]
sents = []
for m in corpus:
s0 = re.split(r"[。.!?!?]", m.content.strip())
if s0 and s0[0]:
sents.append(f"{m.role}: {s0[0]}")
return " | ".join(sents)
def render(self, include_summary: bool = True) -> str:
"""
把当前 STM 转成字符串:
- 若 include_summary=True 且存在摘要,则先拼摘要;
- 然后按顺序输出各条消息。
"""
chunks = []
if include_summary and self._summary:
chunks.append(f"[STM-SUMMARY] {self._summary}")
for m in self.turns:
chunks.append(f"{m.role}: {m.content}")
return "\n".join(chunks)
@property
def summary(self) -> str:
"""返回当前的极简摘要文本(可能为空字符串)。"""
return self._summary or ""
def clear(self):
"""清空短期记忆及摘要,用于“强制重置上下文”的场景。"""
self.turns.clear()
self._summary = None上述短期记忆实现适用于单一对话场景,在实际应用中通常为多会话/多并发场景,此时,应为每个会话生成一个短期记忆实例并绑定会话ID。
3.长期记忆(LTM):内存向量库 + 相似检索
长期记忆的目的是存储那些长期有效的信息,以便在面对新问题时能够高效准确地进行回忆,以提供有价值的信息。但这里的“长期”也并不意味着“永久”,而应是在与具体场景或记忆策略中“长期”概念相契合的时间范畴。例如对于本篇的示例程序而言,这个“长期”代表的是示例程序的运行期间,即在程序退出前,长期记忆里的信息应当一直保留。
长期记忆的信息存储由VSItem类实现,每个VSItem类实例存储一条长期记忆消息。与短期记忆的存储类相比,VSItem类除存储消息原文外,还存储了该原文所对应的向量(向量是进行语义比较的基础)及附加元信息,它实际上实现了一个简单的内存向量库。
VSItem类的具体实现代码如下。
@dataclass
class VSItem:
"""
向量库条目:
- id:内部递增ID;
- text:原文片段(本例存“用户说的话”或知识点);
- vector:对应的向量表示;
- meta:附加元信息(如 salience);
- ts:时间戳(可用于“新鲜度”策略)。
"""
id: str
text: str
vector: List[float]
meta: Dict[str, Any] = field(default_factory=dict)
ts: float = field(default_factory=now_ts)长期记忆的实现则由“写入”与“检索”两部分构成,它们分别由InMemoryVectorStore类的add()和search()方法实现。
add()方法的逻辑很简单,它接收一系列参数,包括要存储的消息原文及其向量等信息,然后生成一个ID作为Key并将消息存入字典。参数中消息原文与向量的对应关系由调用add()方法的代码保证。
search()方法根据参数中传入的查询向量比较它与长期记忆中的每一个条目的相似度(本示例采用余弦相似度)并返回其中得分最高且达到过滤阈值的几个(具体个数由参数指定)条目作为结果。
InMemoryVectorStore类的实现代码如下。
class InMemoryVectorStore:
"""
纯内存向量库(最小实现):
- add(text, vector):添加条目
- search(query_vec, k, min_score):基于余弦相似度做TopK检索
说明:
- 生产可替换为 FAISS/pgvector/ES 等,接口保持一致即可。
"""
def __init__(self):
self.items: Dict[str, VSItem] = {}
self._id = 0
def add(self, text: str, vector: List[float], meta: Optional[Dict[str, Any]] = None) -> str:
self._id += 1
_id = f"mem_{self._id}"
self.items[_id] = VSItem(id=_id, text=text, vector=vector, meta=meta or {})
return _id
def search(self, query_vec: List[float], k: int = 4, min_score: float = 0.1) -> List[Tuple[VSItem, float]]:
"""
相似检索:
- 输入:query_vec(查询向量),k(返回条数),min_score(过滤阈值);
- 输出:[(VSItem, score), ...],按相似度降序;
- 这里只做最简单的线性扫描,足够示例用。
"""
scored = ((it, cosine(query_vec, it.vector)) for it in self.items.values())
topk = [p for p in nlargest(k, scored, key=lambda p: p[1]) if p[1] >= min_score]
return topk上述示例代码用“纯内存 + 余弦相似度”的最小实现完成了embed → add/search的闭环。在实际生产项目中,可将这套接口无缝替换为FAISS(Facebook AI Similarity Search,用于对稠密向量做高效的相似度搜索与聚类)、pgvector(Postgres 插件,关系型 + 向量)或OpenSearch/Elasticsearch k-NN(分布式、向量 + 文本/结构化混检)。而在这个过程中保持了统一的VectorStore适配层,对上仍然暴露add()与search()方法即可。
4.何时写入长期记忆(LTM):salience启发式
长期记忆中的信息被长期保存,因而哪些信息应记入长期记忆是一个需要认真考虑的问题。如果长期记忆写入太多信息,那么长期记忆也许将成为噪声,或者写入太少,又造成“失忆”,无论哪种情况发生,长期记忆都将失去其作用。
在不同场景下,应拟定不同的长期记忆的写入策略。在示例程序中,采用简单可控的“新颖度+关键词提示”启发式评分策略,其概念定义及计算规则如下:
1)新颖度:novelty = 1 – max_similarity(max_similarity为与库内最相似条目的相似度)
2)关键词提示:是否包含“记住/我的偏好/我喜欢/prefer/remember”等显式指令或偏好信号
3)综合评估:salience = 0.7 * novelty + 0.3 * hint,当 salience ≥ 0.55 时写入。
以下代码片段中的estimate_novelty()函数计算新颖度,important_hint()函数检查是否出现关键词,compute_salience()函数则进行综合评估计算综合得分。
HINT_WORDS = ["记住", "我的偏好", "我喜欢", "不要忘", "prefer", "i like", "my preference", "remember"]
def estimate_novelty(store: InMemoryVectorStore, embedder: ZhipuEmbedder, text: str) -> float:
"""
新颖度估计:1 - 与“库内最相似条目”的相似度
- 若库为空 → 新颖度=1.0(全新信息);
- 否则:embed(text) → search Top1 → 取 best_score → novelty = 1 - best_score;
- 该数值用于避免重复存储“差不多”的内容。
"""
if not store.items:
return 1.0
qv = embedder.embed([text])[0]
hits = store.search(qv, k=1, min_score=0.0)
best = hits[0][1] if hits else 0.0
return max(0.0, 1.0 - best)
def important_hint(text: str) -> float:
"""是否出现“请记住/偏好”等关键词(出现则返回1.0,否则0.0)。"""
t = text.lower()
return 1.0 if any(h in t for h in HINT_WORDS) else 0.0
def compute_salience(store: InMemoryVectorStore, embedder: ZhipuEmbedder, user_msg: str) -> float:
"""
综合打分(0..1):salience = 0.7 * 新颖度 + 0.3 * 关键词提示
- 分数高,越“值得写入长期记忆”。
- 你可以按业务调整权重/规则(如加入用户显式“标记记住”的指令)。
"""
lower_msg = user_msg.lower()
question = bool(re.search(r"[??]", user_msg))
explicit_remember = any(k in lower_msg for k in ["记住", "不要忘", "remember"])
hint = important_hint(user_msg)
# 问句默认不写入 LTM;只有显式要求“记住/不要忘/remember”时才保留
if question and not explicit_remember:
return 0.0
# 打招呼等超短消息且无提示词时,不写入 LTM
if not hint and len(tokenize(user_msg)) < 4:
return 0.0
novelty = estimate_novelty(store, embedder, user_msg)
return max(0.0, min(1.0, 0.7*novelty + 0.3*hint))在实际应用中,可能需要采用更复杂的策略更新长期记忆,例如对偏好类与高风险类采用不同阈值与白名单策略;对过旧记忆做时间衰减与归档等。
5.MemoryManager:统一接口与粘合层
MemoryManager类用于管理记忆,它负责把短期记忆与长期记忆串起来,对上层(Agent主循环)暴露以下几个接口:
observe_user()/observe_agent():分别把用户消息和助手消息(大模型回复的消息)纳入短期记忆;
retrieve_for():根据“query + STM 摘要”检索长期记忆,召回相关信息并生成完整的上下文包;
maybe_persist():依据启发式评分策略选择性写入长期记忆。
MemoryManager类的代码如下。
class MemoryManager:
"""
对外提供三个能力:
1) observe_user / observe_agent:把每一轮的 user/assistant 消息纳入 STM;
2) retrieve_for:给定 query,返回“STM 文本 + LTM 命中TopK”,用于拼提示词;
3) maybe_persist:依据 salience 决定是否把用户消息写入 LTM。
"""
def __init__(self, embedder: ZhipuEmbedder, store: InMemoryVectorStore,
stm_max_turns: int = 12, stm_max_words: int = 800):
self.embedder = embedder
self.store = store
self.stm = ShortTermMemory(stm_max_turns, stm_max_words)
def observe_user(self, text: str):
"""把用户消息塞进 STM。"""
self.stm.append("user", text)
def observe_agent(self, text: str):
"""把助手回复塞进 STM。"""
self.stm.append("assistant", text)
def maybe_persist(self, user_msg: str, threshold: float = 0.55) -> Optional[str]:
"""
若 salience ≥ 阈值,则把用户消息写入 LTM。
- 返回:写入后的条目ID;若不满足阈值则返回 None。
"""
sal = compute_salience(self.store, self.embedder, user_msg)
if sal >= threshold:
vec = self.embedder.embed([user_msg])[0]
return self.store.add(user_msg, vec, meta={"salience": sal})
return None
def retrieve_for(self, query: str, k: int = 4) -> Dict[str, Any]:
"""
根据当前问题检索上下文:
- 把 STM 的摘要拼在 query 后(能提升“与当前对话语境一致”的召回);
- 用向量检索拿到 LTM TopK 命中;
- 返回 { "stm_text": ..., "ltm_hits": [{"text":..., "score":...}, ...] }
"""
q = query if not self.stm.summary else f"{query} || {self.stm.summary}"
qv = self.embedder.embed([q])[0]
hits = self.store.search(qv, k=k)
return {
"stm_text": self.stm.render(),
"ltm_hits": [{"text": it.text, "score": float(sc)} for it, sc in hits]
}6.将记忆注入提示词
将记忆注入提示词通过build_system_prompt()函数实现,将MemoryManager类的retrieve_for()方法返回的结果(包含短期记忆摘要文本、短期记忆近期对话及长期记忆 Top-K)作为它的参数传入,它将参数中的信息注入系统提示词,生成可对当前对话提供上下文信息的完整系统提示词。
build_system_prompt()函数的具体代码如下。
def build_system_prompt(ctx: Dict[str, Any]) -> str:
"""
把“短期对话摘要 + 长期记忆TopK”拼进 system prompt:
- 让 LLM “知道你说过什么 & 你曾经的偏好/事实”;
- 仍要求 LLM 结合常识与当前问题谨慎作答。
"""
stm = ctx.get("stm_text", "")
ltm = ctx.get("ltm_hits", [])
refs = "\n".join([f"- ({h['score']:.2f}) {h['text']}" for h in ltm]) or "(无命中)"
return (
"你是一名中文助理。请在回答时参考“记忆/资料”,但不要生搬硬套;"
"如与用户问题或常识冲突,以用户问题为主。回答要简洁、可执行。\n\n"
f"【短期对话摘要】\n{stm}\n\n"
f"【长期记忆 Top{len(ltm)}】\n{refs}\n"
)将相关记忆注入系统提示词只是使用记忆的一种方法,在具体实践中需要根据不同场景需求设计合适的记忆注入策略。
7.主循环:最小可运行闭环
智能体运行的主体通常都是一个不断与模型交互的循环,对于本示例程序而言,这个循环包含4个主要的步骤:
1)首先将用户消息纳入短期记忆;
2)随后通过retrieve_for()获取系统提示词所需上下文(STM + LTM Top-K);
3)然后调用大模型生成回答,并将回答纳入短期记忆;
4)尝试对本轮用户消息做maybe_persist(),如果满足阈值则将其写入长期记忆。
该循环实现位于run_demo()函数,run_demo()函数开始循环之前读取了配置、初始化了智谱AI的对话与向量化组件及示例程序所定义的内存记忆组件,并拟定了一段对话中的用户所发出的消息。拟定对话被切分为两段,其目的是第一段对话完成后,清空短期记忆,在第二段对话中验证第一段对话中保存的长期记忆是否生效。
run_demo()函数的代码如下。
def run_demo():
# 1) 读取必要配置
api_key = os.getenv("ZHIPUAI_API_KEY", "").strip()
if not api_key:
raise RuntimeError("未找到 ZHIPUAI_API_KEY,请在 .env 或系统环境中设置。")
base_url = os.getenv("ZHIPUAI_BASE_URL") # 可选
llm_model = os.getenv("ZHIPU_LLM_MODEL", "glm-4.5")
emb_model = os.getenv("ZHIPU_EMBED_MODEL", "embedding-2")
# 2) 初始化 ZhipuAI 客户端与组件
client = ZhipuAI(api_key=api_key, base_url=base_url) if base_url else ZhipuAI(api_key=api_key)
chat = ZhipuChat(client, model=llm_model, temperature=0.2, max_tokens=512)
embedder = ZhipuEmbedder(client, model=emb_model)
store = InMemoryVectorStore()
mm = MemoryManager(embedder, store, stm_max_turns=10, stm_max_words=200)
# 3) 示例对话分两段,中间强制清空 STM(LTM 保留)
dialogues = [
[
("user", "你好!"),
("user", "我喜欢乌龙茶,不喜欢太甜的饮料,请记住。"),
("user", "推荐一杯饮料?"),
],
[
("user", "昨天我说我喜欢什么茶?"),
("user", "给个不含糖的下午茶建议。"),
],
]
for idx, dialogue in enumerate(dialogues):
if idx > 0:
mm.stm.clear()
print("\n[STM] 已清空(分段重置上下文)")
for role, content in dialogue:
if role == "user":
# ① 记录用户输入进 STM
print(f"\n[user] {content}")
mm.observe_user(content)
print(f"[STM] 已记录 user 消息,共 {len(mm.stm.turns)} 条")
# ② 基于“当前问题+STM摘要”从 LTM 检索相关记忆,构造 system prompt
ctx = mm.retrieve_for(content, k=3)
sys_prompt = build_system_prompt(ctx)
messages = [
{"role": "system", "content": sys_prompt},
{"role": "user", "content": content},
]
# ③ 询问 LLM 并打印回复,同时把回复也纳入 STM(便于后续问答)
answer = chat.ask(messages)
print(f"[assistant]\n{answer}")
mm.observe_agent(answer)
print(f"[STM] 已记录 assistant 消息,共 {len(mm.stm.turns)} 条")
# ④ 尝试把“本轮用户话”写入 LTM(若 salience 达阈值)
persisted = mm.maybe_persist(content, threshold=0.55)
if persisted:
print(f"[LTM] 已写入:{persisted}")
else:
# 固定助手语句也纳入 STM,以保持完整上下文
print(f"\n[assistant] {content}")
mm.observe_agent(content)添加启动代码,运行上述循环,可得到如图 3所示的结果,可见“记忆”已经生效,在第二轮对话中智能体依然记得用户的偏好。
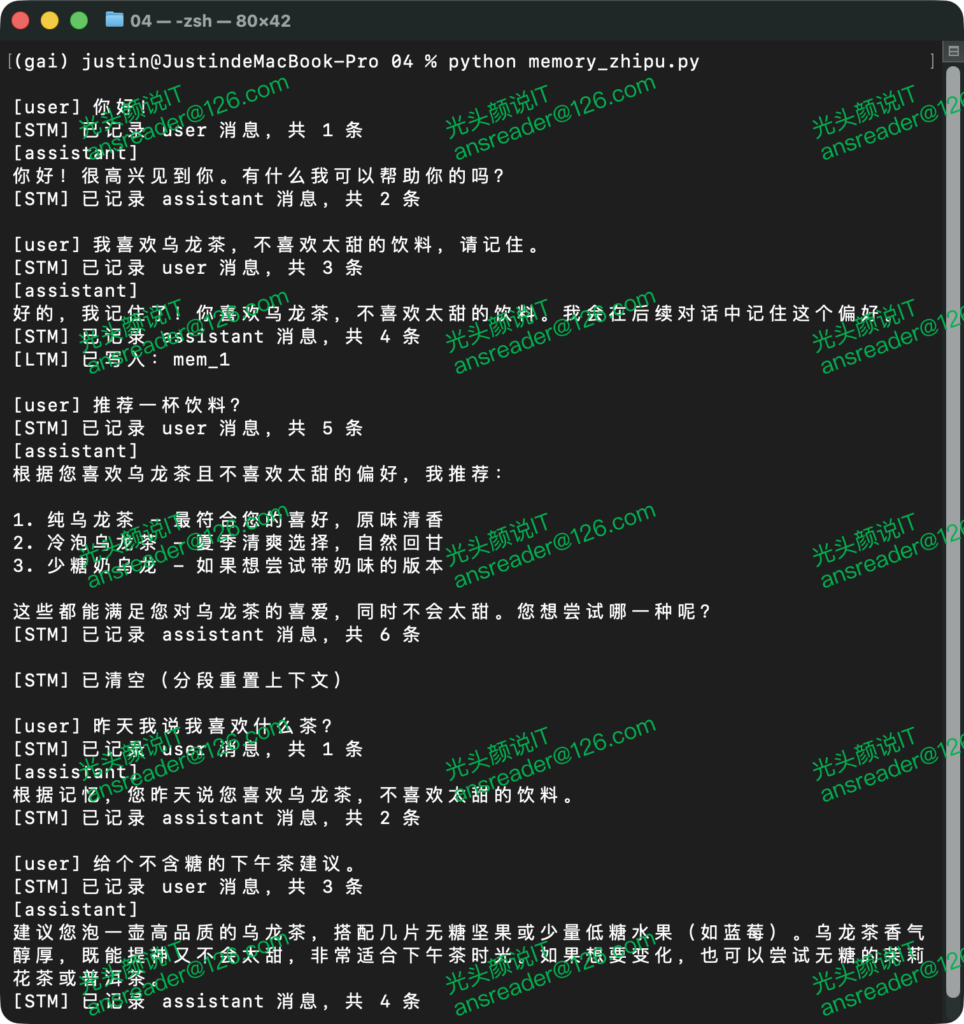
图 3 具有记忆功能智能体的运行结果
在真实场景中,用户的输入应当是“真正”由用户输入或者由应用程序根据需求输入的内容而非硬编码在代码之中。
8.质量与可观测性:指标、日志与回放
工程实践中需要评估智能体记忆相关质量,以判断记忆的有效性。通常可按以下指标进行评估:
1)召回质量:Top-K 平均相似度、命中率;
2)上下文体积:STM + LTM 注入后的 token 估算值;
3)时延与成本:检索 + 生成总耗时、token 成本;
在代码实现中亦可加入回放日志,包括记录检索Query、命中文段、最终系统提示词、模型回答等,以便于定位异常与优化实现。
9.安全、隐私与多租户
本示例程序侧重点在说明记忆的实现,因而未考虑任何安全与隐私因素,实际工程中需特别注意以下几点:
1)敏感数据:写入长期记忆前做脱敏与白名单校验,避免保存密钥、账号等敏感信息。
2)隔离:多用户/多会话需在meta中标记user_id/session_id,或者增加新的标记方法,并在检索时过滤。
3)清除与过期:提供用户侧“查看/删除记忆”接口;对过旧记忆做TTL(Time To Live,生存时间)或衰减处理。
4)合规:遵循企业数据合规要求(采集告知、最小必要、可撤回)。
10.常见问题(FAQ)
Q1:为什么不用“把所有历史对话都拼到上下文里”?
A:成本高(token)、时延大、噪声多;且一旦上下文超长,模型反而会遗忘早期关键事实。采用STM+LTM 的结构更可控。
Q2:为什么摘要不直接用大模型?
A:本示例实现追求最小依赖与稳态可用。需要更高质量摘要时,可在此基础上切换到大模型摘要。
Q3:启发式策略会不会误记?
A:可能。建议加入显式确认、手动记忆开关、领域白名单;同时在检索时提升最小分阈值、做去重等。
Q4:如何扩展为企业级?
A:替换内存向量库为FAISS/pgvector/ES等;加入多租户隔离与权限控制;引入知识库RAG与结构化记忆(例如用户画像表)等。
11.小结
本文系统阐述了将“记忆”引入智能体的必要性与工程化路径,并基于短期记忆+向量库长期记忆给出最小可运行方案。其核心优点包括稳定上下文体积(STM:滚动 + 预算 + 摘要)、可回忆关键事实(LTM:向量化 + Top-K 检索)、接口简洁可复用(MemoryManager)等。
本文示例程序完整代码:
https://gitcode.com/gtyan/AgentHandBook/tree/main/04