
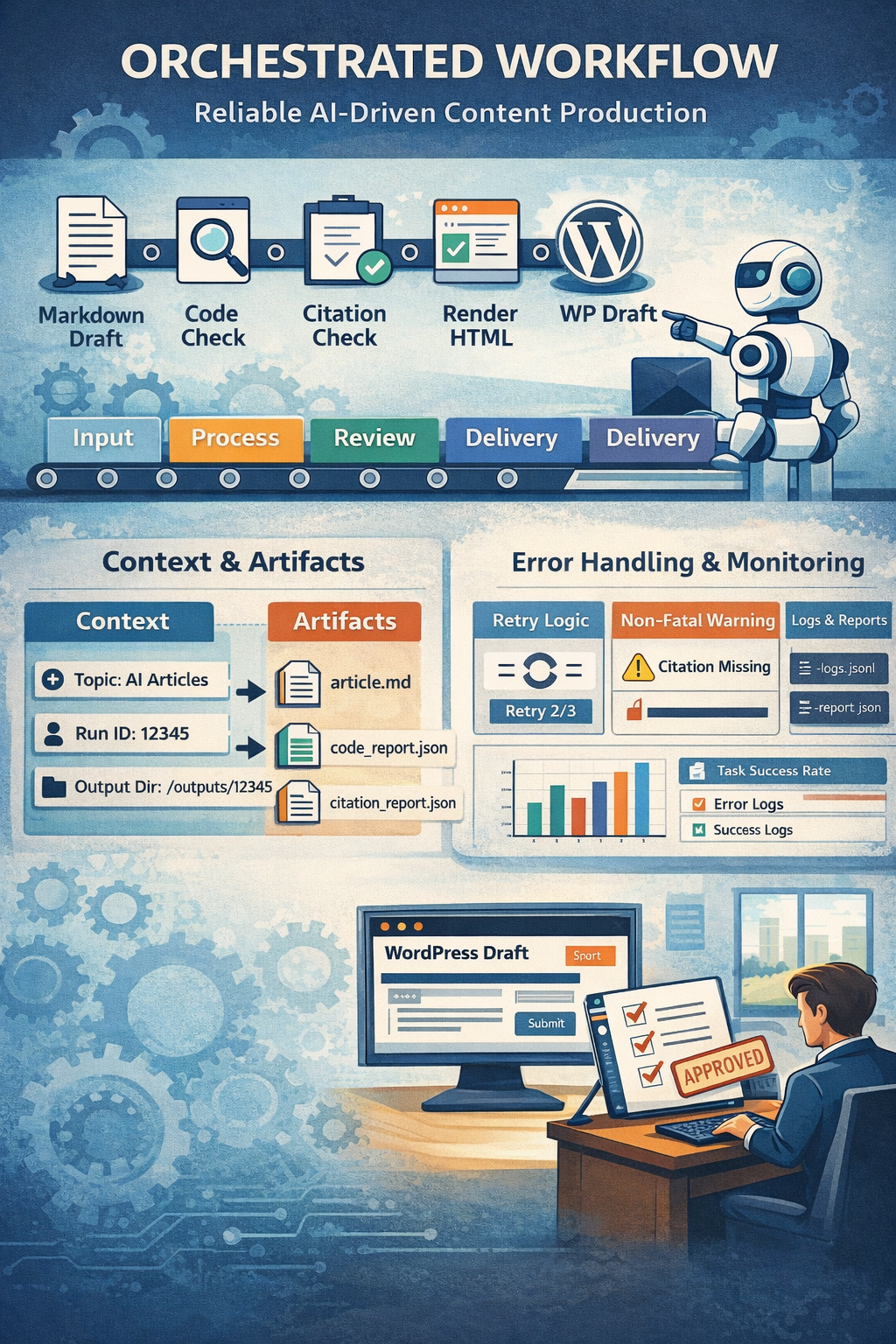
0. 开篇导读:为什么本篇要写“工作流编排”
众所周知,“智能体”可以拆解为一组能力模块:模型(规划)、工具、记忆以及知识接入。而到了真正落地时,会发现最容易踩的坑不是“模型不够强”,而是“交付不够稳”:同一个任务多跑几次结果差异很大;出了错不知道卡在了哪里;产物散落在终端输出里,无法复用与审阅。解决这个问题最常见最有效的手段是使用工作流。
当任务的路径可以被预先枚举时,把它写成一条可执行的流程,会比让模型自由发挥更可靠。很多关于 AI 自动化的讨论都会把“工作流”和“智能体”放在一起比较,它们的核心差异往往不是在某些步骤里“是否使用大模型”,而在“决策是否主要由预设步骤与条件驱动”。工作流强调可预期、可观测、可审计;智能体更擅长开放式探索与动态决策。
本文选择一个非常具体、也非常容易复现的场景:技术文章的内容生产流水线。它的特点是:
- 目标明确,步骤相对固定:先出 Markdown 草稿,再做质量检查,然后渲染 HTML,最后落到 WordPress 草稿;
- 质量标准通过检查验证:例如代码块能不能跑、参考资料是否齐全、HTML 结构是否适配发布平台等;
- 风险动作需要门禁:自动化与人工审核明确分工。
该内容生产流水线最终向 WordPress 提交草稿,其效果如下图:
- 提交后的草稿存在于文章列表

图 1 提交后的草稿存在于文章列表
- 提交 WordPress 的草稿预览效果

图 2 提交 WordPress 的草稿预览效果
这个场景虽然简单但能把“编排”的价值讲清楚:编排不是把任务拆成几段提示词,而是把每一步的输入/输出、失败策略与可观测性做成工程资产。在传统的软件系统里,工作流编排被广泛用于把一组离散任务串成端到端流程,并在步骤间传递数据、处理错误。类似的原则同样适用于 AI 管线:拆分任务、显式依赖、超时与重试、以及对失败的分级处理等。
本篇示例会做什么
示例程序不会追求“全自动发布”,而是把流程收敛为一个可复用的最小闭环:
- 生成 Markdown 初稿(模型只负责这一段创造性输出);
- 代码块可运行性校验(若存在
```python代码块则执行并产出报告;若没有则跳过但仍产出报告); - 引用检查(检查是否包含“参考资料”小节与链接,产出报告);
- 渲染 HTML(同时生成可本地预览的整页 HTML,以及更贴近 WordPress 编辑器展示的内容片段);
- 创建 WordPress 草稿(
status=draft),后续由人工在后台审核并发布。
为了让流程具备“可运维”的基本形态,示例还会把每一步的开始/结束/跳过/失败事件写入结构化日志(JSONL)。结构化日志的价值在于:它更容易被检索、过滤与统计,也更适合做后续的质量指标沉淀与批量分析。
什么时候适合用工作流,什么时候不适合
正式开始“工作流”的讲解之前,有必要先明确“工作流”不是万能的。简略而言可以通过以下直觉判断:
- 当任务的路径可枚举、且你更关心稳定交付与可追溯时,工作流往往更合适;
- 当任务高度开放、需要大量探索与即时澄清,或者关键质量标准难以落地为检查时,工作流的收益会显著下降。
更系统的“适用/不适用”判断标准,以及常见反例与工程取舍,将在后文单独展开。
1. 工作流的核心特征:编排到底带来了什么
在 AI 应用的工程语境里,“编排”并不是把任务拆成几段提示词、按顺序问模型这么简单。对它更准确的描述是把一个端到端目标拆成若干可枚举步骤,并让系统对步骤之间的依赖、失败处理、以及过程可观测性负责。
结合本篇的文章内容生产示例(Markdown 草稿 → 校验 → 渲染 → WordPress 草稿),可以用五个关键词来概括编排带来的价值:路径、契约、容错、可观测、门禁。
1.1 路径:把“做什么”从对话里搬到流程里
工作流首先提供的是一条“预设路径”:它要求明确列出步骤清单,定义顺序与依赖,并据此得到可预期的执行过程。与其寄希望于模型每次都能“自发地想对下一步”,不如把“下一步是什么”固定下来,把不确定性压缩到少数确实需要生成能力的环节(例如在本例中是写作初稿)。
这种设计的直接收益是:
- 可复跑:同一主题可以多次运行,产物结构一致;
- 可定位:如果失败,它一定发生在某一步,而排查失败将从“对话抽丝剥茧”变成“对步骤对号入座”;
- 可扩展:新增关卡(例如结构检查、图片检查)只需增加相应步骤并挂到路径上即可。
在示例工程里,“路径”由入口文件的顺序执行体现(app/main.py),而不是由模型在运行时临场决策。
1.2 契约:让步骤之间通过“产物”协作,而不是互相牵扯
编排要长期可维护,靠的不是更多的 if/else,而是清晰的步骤契约。
本篇示例采用了一个非常务实的策略:每一步都围绕 Context + Artifacts 工作:
Context承载最少且必要的信息(主题、渠道、run_id、输出目录);Artifacts作为跨步骤传递载体,只传递可落盘、可复用的结果(例如article.md、article_wp.html、*_report.json的路径)。
这种“以产物为中心”的协作方式有两个隐含好处:一是步骤天然可替换(比如把渲染器从 Markdown 换成别的实现);二是流程天然支持“降级与跳过”,因为后续步骤只关心自己需要的产物是否存在。
1.3 容错:把失败变成一等公民(超时、重试、分级处理)
一旦流程引入外部系统(模型 API、网络、WordPress),失败就不再是例外,而是常态。编排的价值,恰恰体现在“失败应该怎么处理”这件事上。
但需要强调的是:有了重试,并不代表系统就可靠了。重试会放大副作用,因此工作流中的步骤(尤其是会写入外部系统的步骤)必须考虑幂等性,即同一操作被执行多次时,系统仍应保持一致的业务结果,而不是重复创建资源或重复写入。
幂等性(Idempotence)是一个源自数学和计算机科学的概念。简单来说,它的核心含义是:无论你执行一次还是多次,结果(或系统的状态)都是一样的。
回到本篇示例,我们刻意把“失败”分为三类:
- 必须中止:例如草稿生成失败,后续没有输入可用;
- 非致命失败:例如引用不足、代码块运行失败,依然产出报告并继续渲染与提交草稿,交由人工修订;
- 可跳过:例如文章没有
```python代码块时,校验步骤跳过但仍落盘一份最小报告。
这类“失败分级”是工作流编排的核心工程决策:它把流程从“要么全成功、要么全失败”变成“尽可能交付可用产物,并把风险显式暴露出来”。
1.4 可观测:让流程具备“可运维”的最低形态
编排的另一个特性是可观测性。所谓可观测,并不等于打印更多日志,而是让系统通过结构化的遥测数据暴露内部状态,便于定位问题并做统计分析。
本篇示例用最小实现达成两类可观测输出:
- Trace(JSONL 事件流):每一步记录 start/end/skipped/failed_nonfatal,并附带关键字段(run_id、产物路径等);
- Report(质量报告):把代码块执行结果、引用检查结果写成 JSON 文件,后续可直接被脚本读取做汇总。
对读者来说,这些产物比“控制台看起来没报错”更重要:它们决定了你能否把工作流纳入批量生产、CI 校验、或团队协作流程中。
1.5 门禁:把高风险动作留给人工,把自动化压在“草稿层”
在内容生产场景里,“发布”通常是高风险动作:一旦发布,对外承诺、合规风险、品牌风险都会被放大。因此,本篇示例刻意把自动化边界收敛到“创建草稿”。
这种做法背后的编排思想是:工作流负责把产物推到可审阅的位置,并把质量信号(报告、日志)一并交付;是否发布由人工最终确认。这并不是“自动化不彻底”,而是把人机协作做成显式门禁——在企业场景中,这往往是最现实、也最易落地的策略。
总而言之,工作流的编排价值,并不在于它能让模型更聪明,而在于它能让系统更可靠地交付。通过工作流得到的是一条可复跑的路径、一组可复用的产物契约、一套可控的失败策略,以及一份可运维的过程记录。
2. 本文示例的最小闭环:一条可交付的内容生产流水线
前文提及“编排”的增量包含路径可预设、步骤有契约、失败可分级、过程可观测、风险可门禁。接下来示例代码把这些原则落到一个最小闭环里,目标只有一句话:一次运行,产出一组可审阅、可复用、可投递的文章产物。
所谓“最小闭环”,并不是步骤越少越好,而是要满足三个工程条件:
- 输入明确:只需要一个主题(
--topic),其余配置可选; - 产物落盘:不依赖终端输出,所有关键结果都写成文件;
- 可投递:对接外部系统时,默认只做低风险动作(本示例中是 WordPress 草稿)。
2.1 流水线结构:从“生成”到“交付”的五步主线
本示例将内容生产拆成五步,形成从“生成”到“交付”的端到端链路(入口在 app/main.py):
- draft_markdown:调用会话模型生成 Markdown 草稿,并做必要的后处理与兜底(保证结构与代码块规范);
- code_block_check:若草稿包含
```python代码块,则逐块执行并生成报告;若不包含,则跳过但仍生成最小报告; - citation_check:检查草稿是否包含“参考资料”小节与链接,并输出引用报告;
- render_html:将 Markdown 渲染为两份 HTML:
article.html:可本地预览的整页 HTML;article_wp.html:更适合作为 WordPress 正文投递的内容片段;
- wordpress_draft:若配置了 WordPress 站点与应用密码,则通过 REST API 创建
status=draft的草稿,并返回 post id/link。
其中,只有第 1 步依赖 LLM 的生成能力;后续步骤尽量确定化(检查、转换、落盘、投递),这是工作流在“内容生产”这类场景里能显著提升稳定性的关键。
下面是入口层的关键编排节选:步骤顺序由系统推进,且“无代码块则跳过”“非致命失败继续”都在这里显式定义。
# app/main.py(节选):入口编排 + 跳过/非致命失败策略
run_id = datetime.now().strftime("%Y%m%d-%H%M%S")
tracer = Tracer(path=os.path.join(s.traces_dir, f"{run_id}.jsonl"))
ctx = WorkflowContext(topic=args.topic, channel=args.channel, run_id=run_id, output_dir=s.output_dir)
# 1) 生成 Markdown 草稿
_run_step("draft_markdown", draft_step(llm), ctx, tracer, max_retries=1, backoff_sec=1.0)
# 2) 代码块检查:有则执行;无则跳过但仍落盘最小报告
md_path = ctx.artifacts.get("article_md_path")
md_text = Path(md_path).read_text(encoding="utf-8") if md_path and os.path.exists(md_path) else ""
if md_text and _has_python_code_blocks(md_text):
try:
_run_step("code_block_check", code_step(s), ctx, tracer, max_retries=0)
except RuntimeError as exc:
tracer.log("code_block_check", "failed_nonfatal", message=str(exc))
else:
out_dir = Path(s.output_dir) / run_id
out_dir.mkdir(parents=True, exist_ok=True)
report_path = out_dir / "code_blocks_report.json"
report_path.write_text(
json.dumps({"found_blocks": 0, "executed_blocks": 0, "passed": True}, ensure_ascii=False, indent=2),
encoding="utf-8",
)
ctx.artifacts["code_blocks_report_path"] = str(report_path)
tracer.log("code_block_check", "skipped", reason="no_python_code_blocks")
# 3) 引用检查(不足视为非致命,继续渲染/投递草稿)
try:
_run_step("citation_check", cite_step(), ctx, tracer, max_retries=0)
except RuntimeError as exc:
tracer.log("citation_check", "failed_nonfatal", message=str(exc))
# 4) 渲染 HTML(完整页面 + WP 片段)
_run_step("render_html", render_html_step(), ctx, tracer, max_retries=0)
# 5) 创建 WordPress 草稿(未配置则跳过)
_run_step("wordpress_draft", wp_draft_step(s, wp), ctx, tracer, max_retries=1, backoff_sec=2.0)
2.2 交付物清单:让“跑完了”变成可核验的结果
工作流是否真正可交付,不取决于你在终端看到一句“Done”,而取决于你能否拿到一组可检查、可追踪的产物。本示例每次运行都会生成一个 run_id,并在 outputs/<run_id>/ 下落盘核心产物:
article.md:文章源稿(后续所有关卡的“单一事实来源”);article.html:本地预览整页(用于快速检查排版与代码高亮效果);article_wp.html:WordPress 正文片段(用于投递草稿,减少主题渲染差异);code_blocks_report.json:代码块执行报告(逐块记录 returncode/stdout/stderr/超时等信息);citation_report.json:引用检查报告(收集链接并标记是否缺少“参考资料”小节);.traces/<run_id>.jsonl:结构化事件日志(记录每一步 start/end/skipped/failed_nonfatal)。
2.3 “可投递”的关键:一份内容,两种 HTML 形态
很多人第一次做内容生产管线时会忽略一个事实:同一份 Markdown 在不同发布平台的最终展示差异很大。因此,本示例把 HTML 分成两份,以“用途”来驱动结构:
article.html面向本地预览:完整 HTML 页面 + 基础 CSS + 代码高亮样式,适合在浏览器直接打开;article_wp.html面向 WordPress 投递:只保留正文内容片段,并对常见结构做轻量“WP 友好化”(例如代码块与表格的包装),以更贴近 Gutenberg/主题渲染。
2.4 为什么说它是“工作流”,而不是“多轮提示词”
如果你把上面的五步理解为“我问模型五次”,那就会错过编排的本质。这个最小闭环之所以是工作流,是因为它具备以下三点:
- 步骤由系统负责推进:顺序、依赖、重试与降级都在编排层定义(
app/main.py),而不是由模型临场决定; - 步骤间通过产物契约连接:每一步只写入
artifacts中的文件路径与结果摘要,后续步骤按需读取; - 失败策略是显式的:某些失败必须中止(例如没有草稿输入),某些失败允许继续交付(例如代码块失败也产报告并继续渲染/投递草稿)。
因此,“跑通闭环”的验收标准也很直接:不是去看模型“写得如何”,而是要核验 outputs/<run_id>/ 与 .traces/<run_id>.jsonl 是否齐全,报告是否提示需要人工修订的风险点,草稿是否已在 WordPress 后台等待审核。做到这一点,就拥有了一条可复用的内容生产流水线,而不是一次性的对话产出。
3. 编排如何落到代码:四个“工程抓手”
到这里,已经有了一条清晰的主线:用工作流把“写作”变成“可交付的流水线”。但要把工作流写成一个可长期维护的工程资产,仅仅把步骤按顺序串起来还不够。
实现内容生产工作流还需要四个最关键、也最容易被忽略的“工程抓手”:上下文与产物、步骤化、重试与幂等、观测与报告。它们分别回答四个问题:流程如何共享信息?步骤如何可替换?失败如何可控?运行如何可诊断?
3.1 上下文与产物:用 Context + Artifacts 管住“跨步骤协作”
很多“看起来是工作流”的代码,最后都会演化成一团糟:变量在各处读写、步骤互相调用内部函数、某一步偷偷依赖了另一步的中间态。其直接原因只有一个——步骤之间没有清晰的协作边界。
本篇示例采用的是最务实的一种边界:
WorkflowContext(见app/workflow.py)承载最少必要的“运行语境”,例如topic/channel/run_id/output_dir;artifacts作为跨步骤传递数据的唯一通道,只传递“可落盘、可复用”的结果,通常是文件路径(例如article_md_path/article_wp_html_path)以及少量摘要字段。
这套模式的好处在于:
- 避免隐式耦合:步骤 A 不需要知道步骤 B 的内部逻辑,只要知道“我需要的产物路径是否存在”;
- 天然支持降级/跳过:某一步失败或跳过时,只要仍能产出符合契约的“最小产物”(例如最小报告),后续步骤就不必被迫中止;
- 便于版本化与回放:产物全部落盘,后续可以针对同一个
article.md反复跑校验/渲染,而不必重新生成。
在工作流里, 可以把artifacts理解为步骤之间的“API”。
# app/workflow.py(节选):Context + Artifacts + StepResult
@dataclass
class WorkflowContext:
topic: str
channel: str
run_id: str
output_dir: str
artifacts: Dict[str, Any] = field(default_factory=dict)
wordpress_post_id: Optional[int] = None
@dataclass
class StepResult:
ok: bool
message: str = ""
data: Dict[str, Any] = field(default_factory=dict)
3.2 步骤化:把每一步写成可替换单元,而不是写成一段大脚本
工作流是否“可维护”,本质取决于步骤是否“可替换”。一段大脚本当然也能跑通,但它难以支撑迭代:你想加一个关卡、换一个渲染器、把 WordPress 换成别的 CMS,都会牵一发动全身。
本篇示例把每一步都封装为一个独立模块(见 app/steps/*),并通过 make_step(...) 将依赖注入进去(例如 LLM 客户端、Settings、WordPressClient)。入口侧只做两件事:
- 调用步骤函数并接收
StepResult; - 将步骤的
data合并进ctx.artifacts(见app/main.py::_run_step)。
这种组织方式会带来非常直接的工程收益:
- 可单测:你可以用固定的
WorkflowContext与临时目录跑某一步,验证其产物是否正确; - 可插拔:新增一个关卡就是新增一个
steps/*.py并在入口挂载,不必改动既有步骤; - 可移植:同一个步骤可以被多个工作流复用(例如“引用检查”不仅对文章有用,对方案/报告同样适用)。
3.3 重试与幂等:把“不稳定”当成现实,并把副作用控制住
一旦流程接入外部系统(模型 API、网络请求、WordPress 写入),失败就不再是异常,而是事实。编排层必须显式处理这些不稳定:
- 超时:避免某一步无限等待;
- 重试:对瞬时错误做有限次数的重试;
- 退避:用递增等待降低拥塞,提升成功概率;
- 失败分级:决定哪些失败必须中止,哪些可以继续交付。
示例里,这套策略被压缩为一个非常“干净”的实现:app/main.py::_run_step 统一承接重试与退避参数;不同步骤通过 max_retries/backoff_sec 体现差异(例如草稿生成允许重试一次,草稿创建允许重试一次;而渲染与检查则默认不重试)。
但这里有一个必须单独强调的点:重试会放大副作用。因此,只要某一步会写入外部系统(例如创建 WordPress 草稿),你就需要认真对待幂等性:同一操作被执行多次时,系统仍应保持一致的业务结果,而不是重复创建、重复通知、重复扣费。
本篇示例通过两种方式降低风险:
- 自动化边界收敛到“草稿层”(即便重复创建草稿,也比重复发布可控);
- 在工程上保留
run_id与完整产物落盘,为后续引入“去重键/幂等键”(例如把run_id写入自定义字段或标题后缀)预留空间。
读者可以把这一节当作一个提醒:有重试的工作流,必须同时思考幂等与去重。否则,越自动化越容易制造事故。
# app/main.py(节选):统一封装步骤执行、重试与追踪
def _run_step(name: str, fn, ctx: WorkflowContext, tracer: Tracer, max_retries: int = 0, backoff_sec: float = 1.0) -> None:
attempt = 0
while True:
attempt += 1
tracer.log(name, "start", attempt=attempt)
r = fn(ctx)
tracer.log(name, "end", ok=r.ok, message=r.message)
if r.data:
ctx.artifacts.update(r.data)
if r.ok:
return
if attempt > max_retries:
raise RuntimeError(r.message or f"步骤 {name} 失败")
time.sleep(backoff_sec * attempt)
3.4 观测与报告:让每一次运行都能被解释、被统计、被复盘
最后一个抓手是可观测性。很多流程“看起来能跑”,但一旦失败,排查成本极高:你只看到一段异常堆栈,却不知道失败前已经产出了什么、跳过了什么、外部系统返回了什么。
本篇示例把观测拆成两层:
- Trace(过程事件):用 JSONL 记录每一步的 start/end/skipped/failed_nonfatal,并附带关键字段(见
app/observability.py::Tracer与app/main.py的调用点); - Report(质量信号):把“关卡结果”写成结构化 JSON 文件,例如
code_blocks_report.json与citation_report.json(见app/steps/code_block_check.py与app/steps/citation_check.py)。
这种设计的关键,是把“过程”和“质量”分开:
- Trace 负责回答“发生了什么”;
- Report 负责回答“结果怎么样”。
当你有了这两类数据,很多工程能力就自然出现了:可以统计失败率与耗时,挑出最常失败的步骤;可以把报告接入 CI,把质量关卡变成自动门禁;也可以做批量生产,把每一次运行都沉淀成可追溯的交付记录。
# app/observability.py(节选):最小可观测(JSONL 事件流)
@dataclass
class Tracer:
path: str
def log(self, step: str, event: str, **data: Any) -> None:
rec = {"ts": time.time(), "step": step, "event": event, "data": data}
os.makedirs(os.path.dirname(self.path), exist_ok=True)
with open(self.path, "a", encoding="utf-8") as f:
f.write(json.dumps(rec, ensure_ascii=False) + "\n")
到这里,四个抓手就形成了一个闭环:上下文与产物定义协作边界;步骤化保证可替换;重试与幂等把不稳定与副作用纳入设计;观测与报告让流程具备可运维的最低形态。后文在展开“适用/不适用场景”与“工程取舍”时,这四个抓手会反复出现,它们也是你判断一个工作流是否“真正工程化”的最短清单。
4. 五个步骤的最小说明(每步只回答“为什么需要它”)
到这里,示例程序已经展示了一个很朴素的事实:这条流水线的价值不在“步骤多”,而在“每一步都在为最终交付兜底”。因此,本节刻意不谈“怎么做”,只回答每一步存在的必要性——为什么少了它,闭环就会变得不可靠。
4.1 draft_markdown:为什么必须先有一份可落盘的源稿
工作流要可交付,首先需要一个稳定的“单一事实来源”。把文章源稿落盘为 article.md,这等于把最不确定的生成结果固化为可复用的输入:后续检查、渲染、投递都围绕它进行,而不是围绕终端输出或内存变量。更重要的是,一旦后续关卡失败,你仍然能拿到一份完整草稿用于人工修订,而不是“这次没跑通就什么也没留下”。
4.2 code_block_check:为什么需要把代码可运行性前置为关卡
技术文章里最常见、也最伤读者信任的问题,是代码“看起来对、跑不起来”。把代码块运行检查放进流水线,目的不是追求全自动修复,而是把风险显式暴露出来:哪些代码块能跑、哪些失败、失败原因是什么。即便本篇示例允许“无代码块则跳过”,这一步仍然重要——因为它把“有没有代码、能不能跑”从主观判断变成了可落盘的客观报告。
4.3 citation_check:为什么需要对“参考资料”做最低限度的约束
内容生产一旦进入团队协作或长期连载,引用质量往往会快速下滑:链接缺失、来源不清、后续难以复核。引用检查的意义并不在于评判观点对错,而是确保文章具备可追溯的最小外部支撑:读者知道信息从哪里来,你自己也能在后续迭代时快速回溯。换句话说,这一步是在用极低成本,为内容建立“可审计”的底座。
4.4 render_html:为什么需要在投递前先把渲染问题解决掉
仅有 Markdown 还不足以交付到真实发布环境,因为“同一份 Markdown 在不同平台呈现差异很大”。提前渲染 HTML 的目的是把排版、代码块、表格等问题在本地就暴露出来,避免把所有问题推到 WordPress 后台再返工。更进一步,示例同时输出整页预览 HTML 与面向 WordPress 的正文片段,其本质是在承认平台差异的前提下,为“投递形态”提供更稳定的中间表示。
4.5 wordpress_draft:为什么自动化要止步于“草稿”,而不是直接发布
工作流的最终价值是把结果送到可审阅的位置,并形成可交付的闭环。将文章自动提交为 WordPress 草稿,一方面完成了系统间交接(从本地产物到 WordPress 资产),另一方面保留了人工门禁:由人最终确认、调整与发布。这样设计的目的很明确——让自动化承担“搬运与收敛”,让人工承担“责任与决策”,既降低风险,也更符合真实团队的内容发布流程。
草稿门禁并不是口头约定,而是投递请求里显式固定的状态字段(status="draft")。同时,示例优先提交更贴近 WordPress 展示的 HTML 片段。
# app/steps/wordpress_draft.py(节选):只创建草稿;优先提交 WP 片段 HTML
if not wp:
return StepResult(ok=True, message="未配置 WordPress,跳过创建草稿", data={})
html_path = ctx.artifacts.get("article_wp_html_path") or ctx.artifacts.get("article_html_path")
md_path = ctx.artifacts.get("article_md_path")
if html_path and os.path.exists(html_path):
content = open(html_path, "r", encoding="utf-8").read()
elif md_path and os.path.exists(md_path):
content = "<pre>" + open(md_path, "r", encoding="utf-8").read() + "</pre>"
else:
return StepResult(ok=False, message="未找到可提交到 WordPress 的内容")
# app/wordpress.py(节选):请求 payload 固定为草稿状态
payload = {"title": title, "content": content_html, "status": "draft"}
resp = requests.post(url, headers=self._headers(), json=payload, timeout=self.timeout_sec)
至此,上面五个步骤回答了“为什么需要它们”,但正如文首提到的关键的问题:什么时候值得引入工作流?它有没有可复述的选型标准?以帮助我们在立项与方案评审阶段做判断。
5. 什么时候适合用工作流(选型标准)
前面已经把工作流的“工程价值”讲得很清楚了:它擅长把不确定的智能环节,嵌入到一条可预设、可观测、可交付的流程里。但在真实项目里,最难的并不是“如何写一个工作流”,而是什么时候应该选择工作流,什么时候不该选择工作流。
下文先从“适合”使用工作流的角度给出一套可落地的选型标准,帮助在立项或方案设计阶段做判断。
5.1 最短判断:五个问题,回答越肯定越适合
可以用下面五个问题做快速筛选。它们分别对应工作流最核心的五项收益(路径、契约、容错、观测、门禁):
路径可枚举吗?
- 不是问“能不能拆步骤”,而是问“主路径是否稳定,且失败分支是否可控”。如果一条任务的主链路始终是:获取输入 → 处理 → 校验 → 输出/投递,那么它天然适合被编排。
质量标准能落地为检查吗?
- 工作流之所以能提升交付稳定性,是因为它能把质量从“主观判断”变成“客观信号”。哪怕检查很粗(例如“代码块是否能跑”“是否有参考资料”),只要能落盘成报告,它就能显著降低返工成本。
失败需要被分级处理吗?
- 如果你的系统必须做到“尽可能交付可用产物”,并且把风险点显式暴露给人工审核(而不是直接失败退出),那么工作流非常合适。因为工作流天然擅长把失败拆成:必须中止 / 允许继续 / 可跳过。
过程需要可追溯与可审计吗?
- 一旦任务进入团队协作、批量生产、或需要对外解释(合规/质量/交付证明),你就会需要“运行记录”。工作流把过程事件与质量报告做成明确产物,能把“我觉得跑过了”升级为“我能证明跑过了”。
是否存在高风险动作需要门禁?
- 如果你的流程里包含“不可逆或高成本”的副作用(发布、通知、扣费、写入生产系统),那么工作流尤其适合,因为它允许你把自动化边界收敛到低风险层(例如草稿、预发布、待审核),并把最终决策留给人类。
如果上述问题中 3 个以上都能给出肯定回答,通常就值得进入“工作流优先”的方案设计。
5.2 选型标准的工程化表达:四个维度打分
为了避免“看起来适合”但落地后仍然失控,我建议把上面的判断收敛成四个可量化维度,用于评审或技术方案对齐:
- 可结构化(Structure):路径是否稳定、输入输出是否能标准化、步骤之间能否用产物契约连接;
- 可校验(Verification):质量信号是否可检查、可落盘、可复盘;
- 可恢复(Recovery):失败是否可分级、是否允许重试、外部副作用是否可控(幂等/去重);
- 可运营(Operations):是否需要观测、审计、批量运行、团队协作。
在实操中可以简单用 0–2 分打分(0=不具备,1=部分具备,2=明显具备),总分越高越适合工作流。
- 0–3 分:通常不建议上工作流,先用更轻量的脚本/对话式工具验证价值;
- 4–6 分:可以考虑工作流,但要把“关卡与产物”设计清楚,否则容易变成大脚本;
- 7–8 分:工作流非常合适,建议把可观测与幂等作为一开始的硬要求。
5.3 回到本篇示例:为什么“内容生产”高度符合工作流
用这套标准回看我们的内容生产流水线,你会发现它几乎是“工作流的教科书场景”:
- 路径稳定:生成 → 校验 → 渲染 → 投递,主链路固定;
- 检查可落地:代码块执行报告、引用检查报告都能落盘;
- 失败可分级:检查失败可以继续交付草稿,让人修订;
- 过程要可追溯:写作连载与团队协作需要 run_id、trace 与报告;
- 门禁天然存在:高风险动作保留人工审核。
这也解释了为什么本篇的代码强调 outputs/<run_id>/ 与 .traces/<run_id>.jsonl:工作流的交付对象不仅是文章正文,还包括“可以支撑协作与复盘的工程产物”。
6. 什么时候不适合用工作流(明确反例)
前文讲了“适合”工作流的情况,随后也需要了解“克制”使用工作流的场景。工作流的优势是把主路径固定下来,用产物契约与关卡检查把交付变稳定;但它的代价也很明确:你需要维护步骤、处理失败分级、补齐观测与审计。
因此,当工作流的前提不成立时,它往往不是“让系统更可靠”,而是“让系统更复杂”。下面用五类明确反例把边界画清楚,便于在方案评审时做快速否决或做边界收缩。
6.1 反例一:目标高度开放,路径不可枚举
如果任务的核心价值来自“动态探索”而不是“沿预设路径推进”,工作流很难覆盖它的未知空间。使用工作流时会不断补分支、补兜底,但仍然会遇到新的例外。
典型任务:
- “帮我排查线上系统为什么变慢”:需要持续探查、实验与临场决策;
- “把一个模糊想法推进到 PRD”:澄清问题本身就是工作内容;
- “根据最新资料做趋势研判”:信息源、论证路径与结论取决于探索结果。
这类场景更适合“探索式智能体 + 人机协作”:让系统先搜集与组织信息,再由人决定下一步,而不是用固定编排强行覆盖未知。
6.2 反例二:强交互、强澄清的任务,不适合一次性跑通
工作流天然偏“批处理”:给定输入,按步骤跑完,产出结果。若任务需要频繁与人交互(多轮澄清、持续确认、反复协商),你会在工作流里塞进大量“人工节点”,最终把工作流变成一个笨重的表单系统。
典型任务:
- 客服/销售对话协商:用户诉求会随沟通变化,任何一次确认都可能改变目标;
- 复杂审批中的“边跑边改”:每个意见都会触发方案重写与路径重排;
- 教学/辅导:核心不是一次性产物,而是基于反馈实时调整策略。
工程上更常见的做法是:用会话状态管理与协作 UI 承接交互,把工作流退到“确定性子任务”的层面(例如整理材料、生成版本对比、落盘与归档)。
6.3 反例三:质量不可检查,工作流只能“照跑”
工作流能显著降低返工,一个关键原因是“质量信号可落盘”。如果结果好坏只能靠主观感受判断,那么即便你把它拆成十个步骤,也缺少工程闭环:因为不知道哪里出了问题,也无法把经验沉淀为可复用的门禁。
典型任务:
- 纯创意类写作(无结构标准、无事实依赖、无可执行代码或可核验引用);
- 发散型文案生产(数量可验收,但质量难以客观判定);
- 主观指标驱动的润色(“更有感染力/更高级”缺少可测信号)。
这并不意味着不能上工作流,而是意味着:要么先把质量标准工程化(哪怕只是最小集合),要么就承认它更适合“人审 + 交互式迭代”。
6.4 反例四:副作用不可控,且无法保证幂等/去重
工作流通常会配套重试与恢复机制;一旦重试存在,副作用控制就变得关键。
如果你的关键动作天然不可幂等(或代价极高),工作流很容易把偶发失败放大成事故:一次超时触发重试,结果重复扣费、重复通知、重复写入。
典型任务:
- 直接触发支付/扣费/下单,而下游接口不支持幂等键;
- 向大量用户发送消息/工单/通知,且无法去重或撤回;
- 对生产库做写入/删除,且缺少事务、审计与补偿机制。
这也是为什么本篇示例的自动化边界止步于“创建 WordPress 草稿”:它属于低风险副作用,允许重试,即便重复创建也可人工处理。反过来,越接近“不可逆动作”,越需要用幂等键、去重、补偿与审计把风险压住。
6.5 反例五:超高频、低延迟的事件流处理(工作流不是消息总线)
工作流擅长“跨系统协调”,但不擅长充当“实时事件处理引擎”。当你的核心诉求是毫秒级响应、每秒成千上万事件吞吐时,工作流的状态持久化、历史记录与可追溯机制反而会成为额外开销。
典型任务:
- IoT 高频遥测实时告警(窗口聚合、去抖、限流、流式计算);
- 在线风控/广告实时决策(延迟预算极低);
- 高频交易/撮合链路(确定性与延迟优先级远高于编排可视化)。
这类场景通常需要事件驱动与流处理架构;工作流更适合出现在“后置协调层”(例如补偿、人工复核、跨系统对账),而不是站在实时链路的正中间。
6.6 收敛成三条否决条件:评审时问这三个问题
如果需要在评审会上快速给出结论,建议用三条否决条件收敛:
- 路径不可枚举:核心价值来自动态探索与即时决策;
- 质量不可检查:缺少可落盘、可复盘的客观信号;
- 副作用不可控:重试会放大风险且无法幂等/去重。
任意命中一条,都要谨慎:不是“绝对不能用工作流”,而是应该把工作流退到更小的边界——只编排那些确定性的环节(数据收集、格式转换、落盘与投递),把探索与决策留在对话式智能体或人工审阅层。
7. 小结:把“编排”沉淀成可复用资产
回到本文开头提出的那个问题:为什么要写“工作流编排”?答案现在应该很明确了——当任务的主路径可枚举时,真正决定交付质量的,不是模型“有没有灵感”,而是你是否把流程做成了可复跑、可观测、可审计的工程资产。
这条内容生产流水线之所以值得复用,并不是因为它“写得更像人”,而是因为它把不确定性收敛到了最小范围:
- 创造性输出集中在
draft_markdown,其余环节尽量确定化; - 质量风险通过关卡检查显式化(报告落盘,而不是埋在日志里);
- 高风险动作通过门禁控制(自动化止步于草稿层)。
更重要的是,编排一旦被“资产化”,它的复用形态就不再是一段脚本,而是一组可以被组合、被替换、被运维的模块。你可以把这类资产沉淀成四层:
流程配方(Recipe):步骤清单、执行顺序、重试与失败分级策略。
- 这决定了“系统怎么推进”,而不是“模型怎么想”。
产物契约(Artifacts Contract):每一步输入/输出的最小集合与命名规则。
- 这决定了“步骤怎么协作”,让替换与扩展不至于牵一发动全身。
质量信号(Quality Signals):可以落盘、可复盘的检查报告与统计指标。
- 这决定了“好坏怎么判断”,也是后续接入 CI 门禁与批量生产的基础。
投递适配(Delivery Adapter):面向外部系统的低风险对接层。
- 这决定了“怎么交付到业务现场”,并把副作用风险控制在可管理范围内。
把这四层沉淀下来,“工作流”就不再是一次性工程,而是可以不断积累的生产力:同一套校验与渲染能力可以复用到方案、报告与知识库内容;同一套 trace 与 report 机制可以复用到其他 AI 管线;同一套“草稿层门禁”策略也可以迁移到工单、知识发布、甚至运维脚本的自动化发布流程。
最后给一个实践上的提醒:把编排做成资产,最常见的误区不是“步骤太少”,而是“只有步骤,没有契约与可观测”。当你愿意为 run_id、产物目录、JSONL trace、质量报告这些“看起来不酷”的东西投入一点点工程成本,你就能把 AI 从一次性对话,变成可批量交付的流水线。
示例代码工程: https://gitcode.com/gtyan/AgentHandBook/tree/main/07