

0. 序言
智能体落地的分水岭,通常出现在需要对“答案为何如此”负责的时候。此时,“能调用大模型”已不再是门槛。真正的挑战在于,系统能否在多知识源、多工具、多约束的环境下稳定地产出可复核结果,并在失败时快速定位原因。
本文用一个最小但完整的工程骨架,回答一个具体的工程命题——让一个 Agent 调度另一个 Agent,并将调度从提示词技巧落到可执行、可控、可观测的结构上。示例工程采用 Controller/Worker 模式,将复杂任务拆分为职责清晰的子任务。流程包含路由、取证(SQL 与文档检索)与合成三个阶段,且全过程以 trace 固化为可回放的执行记录。
本文不试图覆盖所有智能体框架,也不以“堆功能”为目标。示例工程的取舍是刻意的。代码尽量少,但结构必须完整。依赖尽量轻,但关键约束必须落地。输出不仅包含答案,还包含依据与路径。阅读方式建议采用“边读边运行”。对照每个 Worker 的职责边界,观察 Controller 的编排方式,并通过 trace 理解工程化智能体与单体 Prompt Agent 的差异。
1. 真实动机:为什么需要 Controller/Worker
如果仅将智能体当作“会聊天的入口”,单体式 Agent 往往够用。但一旦将其作为系统能力的一部分,单体式 Agent 的结构性缺陷会迅速暴露。Controller/Worker 模式并非“架构洁癖”,而是对以下三类工程压力的直接回应。
第一类压力来自决策与执行必须被约束。真实业务中,智能体常常同时面对结构化数据与非结构化文档,还可能拥有进一步的工具调用权限。单体式 Agent 依赖模型在一次对话中“自行决定走哪条路”,容易产生不可控偏航。例如,应查数据库却转向文档“找类似说法”,应给出流程依据却直接凭常识总结。Controller/Worker 的目标是将“走哪条路”显式化。Router 产出可审计的路由决策,Controller 按决策调度对应 Worker,从而避免将关键路径交给隐式推理。
第二类压力来自安全边界必须是硬约束,而不是软提醒。尤其是数据库查询这类能力,提示词再严谨也无法等价于执行层面的规则。示例工程将这件事拆得足够具体。SQL 由模型生成,但执行前必须经过校验,例如只允许 SELECT、限定表、限制 LIMIT、禁止多语句。同时,Worker 处在白名单注册表之内,Controller 不会调度任何未授权能力。系统安全性来自代码路径与执行策略,而不是来自“希望模型听话”。
第三类压力来自可观测与可维护性。工程问题很少以“模型不聪明”的形式出现,更多以“为何走了这条路径”“证据在何处丢失”“从哪一步开始输出为空”等形式出现。Controller/Worker 通过 trace 将过程拆成事实,包括路由结果、SQL/RAG 是否返回证据、证据集合规模,以及合成阶段输入输出是否为空。由此,系统不再只能依赖“调参式修复”,而具备可诊断性。
以上三点共同指向同一结论:当智能体需要处理多源信息、执行受控动作并承担可解释责任时,需要将其从“会说话的黑箱”改造成“由多个可控单元组成的流水线”。Controller/Worker 模式提供了这种最小可行结构。Controller 负责编排与状态流转,Worker 负责受控执行与结构化产出。证据作为中间产物被标准化,trace 作为过程产物被固化。
2. 示例场景:混合知识问答(SQL + 文档 RAG)
示例场景选择企业内部最常见、也最容易“答得像但答不对”的问答形态。关键特征是同一个问题可能同时依赖结构化数据与非结构化文档。结构化数据擅长给出可枚举、可统计、可对齐字段的事实。文档擅长承载原则、流程、规范、升级路径等叙述性规则。将两类信息混在一次自由生成中,常会得到一段听起来合理但无法核验的答案。
示例工程设置两类输入源,包括 SQLite 数据库(data/company.db)与 Markdown 文档(docs/*.md)。数据库用于回答员工、项目、工单等可查询事实。文档用于回答策略、Runbook、升级规则等文本知识。main.py 中的演示问题覆盖了三种典型形态。
examples = [
"新加坡有多少员工?",
"列出正在进行的项目",
"我们的安全策略里提到的最小权限原则是什么?",
"P0工单有哪些?并给出runbook里对P0的升级要求",
"我们有哪些项目?项目负责人部门分别是什么?并说明是否有对应的运维升级流程",
]
三类问题形态如下。
- 纯 SQL:答案本质上是“表里的事实”,例如“新加坡有多少员工”“列出正在进行的项目”。
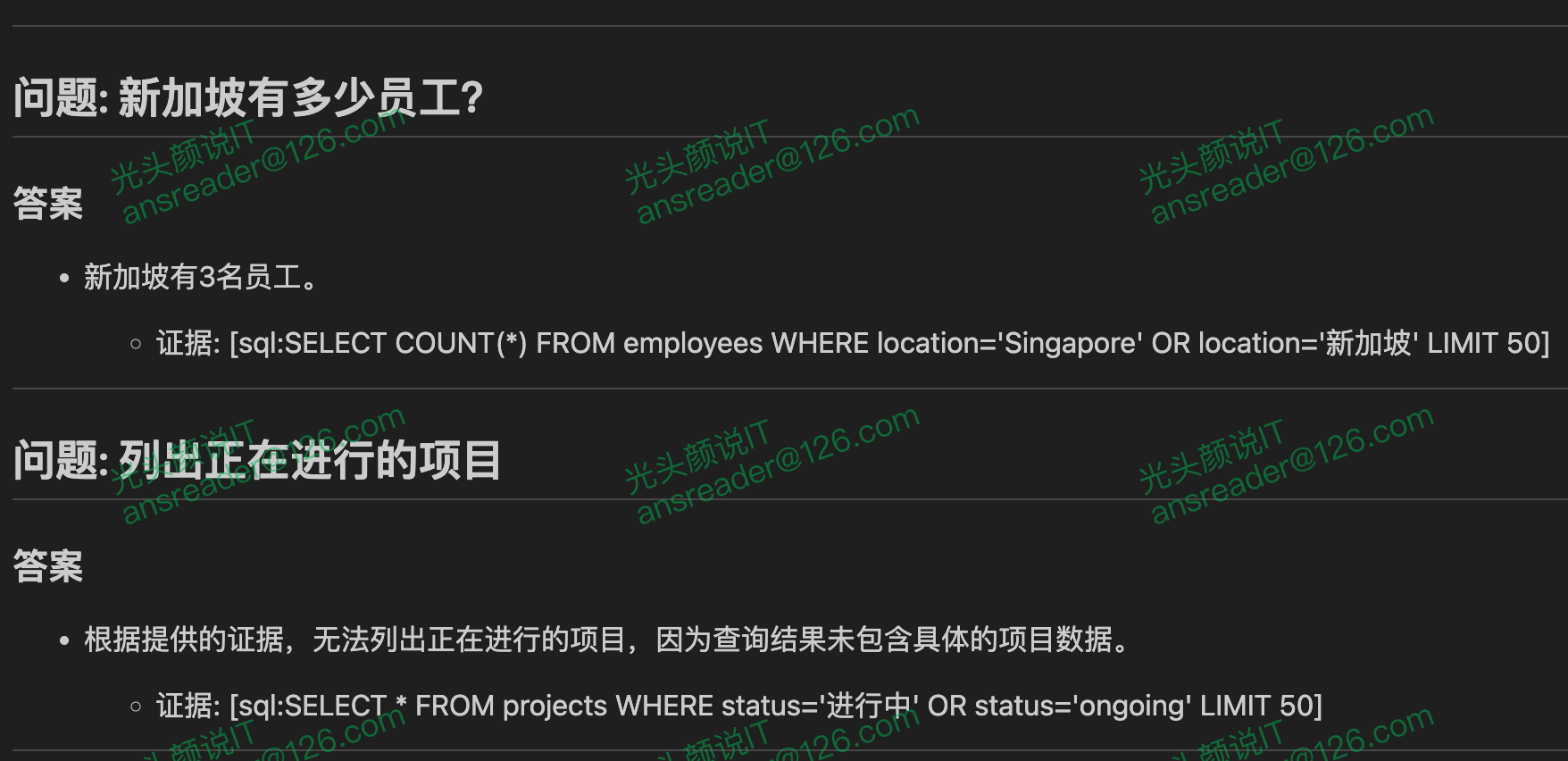
- 纯 RAG:答案来自规则文本,例如“最小权限原则是什么”。

- MIX(SQL + RAG):同一问题同时需要事实与规则,例如“P0 工单有哪些?并给出 Runbook 里对 P0 的升级要求”。只用 SQL 会缺少规范依据,只用 RAG 会缺少当前事实。
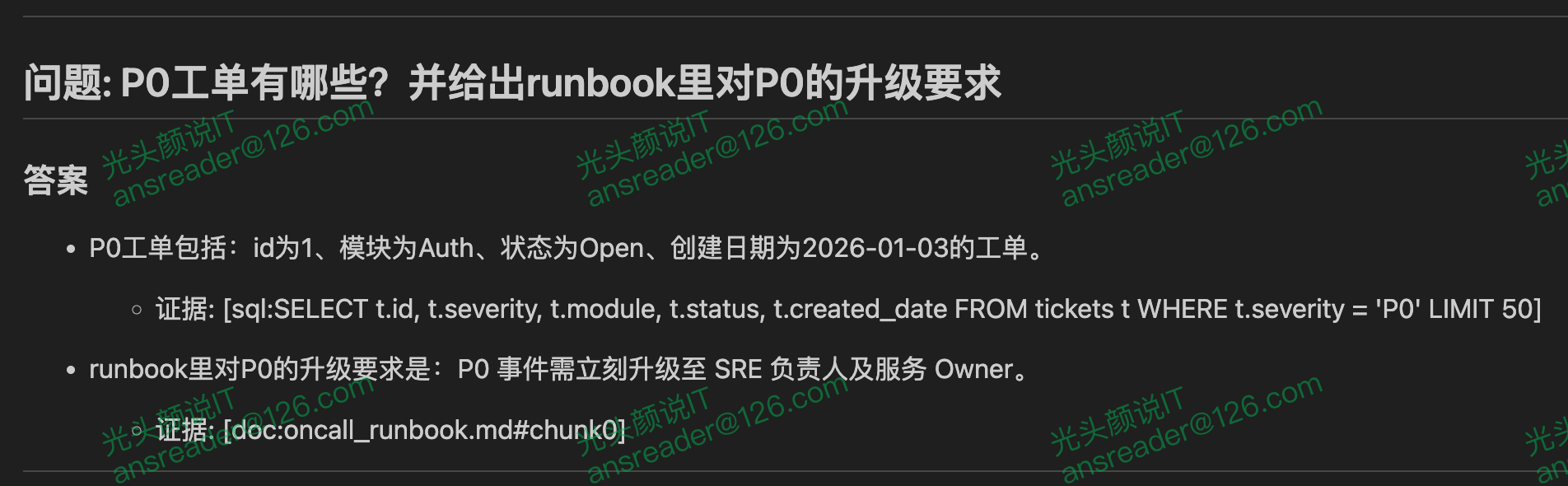
为避免依赖模型“自行决定”,示例工程将“走哪条路”显式化为路由结果(SQL/RAG/MIX),并在 Controller 中用清晰分支调度 Worker。在路由为 MIX 时,两类取证都会执行,证据合并后再进入综合阶段。
3. 架构总览:组件与数据流
设计目标是用最少的组件跑通“编排—证据—合成”链路,并让每一段能力都能锚定到明确的代码职责。
3.1 组件清单:控制面、执行面、数据面
从代码文件与类的划分看,项目分为三层。
- 控制面(Controller):负责编排与产物输出,不实现业务推理。
- 执行面(Workers):每个 Worker 只负责一种可替换能力(路由、SQL、RAG、合成)。
- 数据面(Models/State):用 dataclass 固化问题、路由、证据、诊断、最终包,使数据流可追踪、可扩展。
| 角色 | 代码位置 | 核心职责 | 输入 | 输出(示例形态) |
|---|---|---|---|---|
| AgentController | controller.py | 编排调用顺序、收集 trace,并写入 answer.md/trace.json | question_text | AnswerPackage |
| QueryRouterWorker | workers.py | 决定走 SQL / RAG / MIX | TaskContext | WorkerResult(route=RouteDecision(...)) |
| SQLWorker | workers.py | 生成 SQL → 校验 → 查询 SQLite → 生成证据 | TaskContext | WorkerResult(evidence=EvidenceSet(items=[EvidenceItem(kind="sql", ...)])) |
| RAGWorker | workers.py | 向量检索文档分块,返回文档证据 | TaskContext | WorkerResult(evidence=EvidenceSet(items=[EvidenceItem(kind="doc", ...)])) |
| SynthesisWorker | workers.py | 仅基于证据合成答案,并抽取引用 | ctx.state["evidence"] | WorkerResult(data={"answer": "..."} ) + ctx.state["citations"] |
| ZhipuHTTPClient | zhipu_http_client.py | 统一对话与向量的 HTTP 调用封装 | 请求参数 | 文本/向量 + 诊断字段 |
说明:
EvidenceSet仅负责聚合items。证据类型位于EvidenceItem.kind,而非EvidenceSet本身。
3.2 端到端数据流:路由 → 证据 → 合成
整体执行流在 AgentController.handle() 中被组织为三段式,包括路由、取证与合成。以下为源代码中的连续片段,用于展示编排骨架的固定性。
trace_id = _make_trace_id(question_text)
session = SessionContext(trace_id=trace_id)
ctx = TaskContext(session=session, question=Question(question_text))
self.trace.record("question", {"text": question_text})
# 1) route
router = self.registry.get("QueryRouterWorker")
r = router.run(ctx)
rd = r.route
self.trace.record(
"route",
{
"route": rd.route,
"confidence": rd.confidence,
"rationale": rd.rationale,
"diag": (r.diagnostics.meta if r.diagnostics else {}),
},
)
# 2) evidence
evidence = EvidenceSet()
if rd.route in ("SQL", "MIX"):
sqlw = self.registry.get("SQLWorker")
sr = sqlw.run(ctx)
self.trace.record(
"sql",
{
"status": sr.status,
"diag": (sr.diagnostics.meta if sr.diagnostics else {}),
"msg": (sr.diagnostics.message if sr.diagnostics else ""),
},
)
if sr.evidence:
evidence.extend(sr.evidence)
if rd.route in ("RAG", "MIX"):
ragw = self.registry.get("RAGWorker")
rr = ragw.run(ctx)
self.trace.record(
"rag",
{
"status": rr.status,
"diag": (rr.diagnostics.meta if rr.diagnostics else {}),
"msg": (rr.diagnostics.message if rr.diagnostics else ""),
},
)
if rr.evidence:
evidence.extend(rr.evidence)
ctx.state["evidence"] = evidence
self.trace.record("evidence", {"count": len(evidence.items)})
# 3) synthesis
syn = self.registry.get("SynthesisWorker")
ar = syn.run(ctx)
该骨架体现两点工程事实。第一,MIX 并非“能力随意拼接”,而是在编排层显式触发两条取证链路并汇总证据。第二,合成阶段只读取 ctx.state["evidence"],从流程上切断“绕过取证直接回答”的路径。
3.3 运行产物:答案与轨迹
示例工程将输出拆为两类产物。
answer.md:面向阅读的答案输出trace.json:面向调试与审计的执行轨迹(路由、取证、合成等关键事件)
产物定位清晰后,“证据协议”与“可观测性”的讨论才具备落点。证据用于支撑答案可复核,trace 用于支撑过程可定位。
4. 数据结构设计:让拆解流程可传递、可追踪
Controller/Worker 能否长期成立,关键不在于引入多少 Worker,而在于是否将链路中真正需要传递与审计的内容压缩为少而稳定的数据结构。该实现将数据结构集中在 models.py,刻意只覆盖三类对象,包括上下文、证据与结果。
4.1 TaskContext:唯一输入,最小共享
所有 Worker 的输入都是 TaskContext,由会话元信息 SessionContext、问题 Question 与共享字典 state 组成。
@dataclass
class TaskContext:
session: SessionContext
question: Question
state: Dict[str, Any] = field(default_factory=dict)
跨步骤写入被控制在少量键上。证据集写入 ctx.state["evidence"],引用列表写入 ctx.state["citations"]。共享容器的用途收敛后,状态传递不会演变为不可控的“全局杂物箱”。
4.2 Diagnostics + WorkerResult:统一“可归因结果”
为避免“失败但不可归因”,每个 Worker 的输出被规范为 WorkerResult。其中包含状态、可选路由、可选证据、可选诊断与少量载荷字典。
@dataclass
class WorkerResult:
status: str # "ok" | "empty" | "error"
route: Optional[RouteDecision] = None
evidence: Optional[EvidenceSet] = None
diagnostics: Optional[Diagnostics] = None
data: Dict[str, Any] = field(default_factory=dict)
status 使用三值枚举覆盖主分支。Diagnostics.meta 专门承载排障所需的最小字段,例如 HTTP 状态码、URL、响应预览,从而使 trace 能直接回答“外部依赖到底返回了什么”。
4.3 EvidenceItem + EvidenceSet:把“取证”从文本变成结构
混合知识问答最容易失控的环节通常是合成。模型倾向用常识补齐缺失信息。该实现用 EvidenceItem 将证据压缩为四个字段,分别为 content/kind/source_ref/score。再用 EvidenceSet 装载,并提供 extend() 作为合并方式。
@dataclass
class EvidenceItem:
content: str
kind: str # "sql" | "doc"
source_ref: str # "sql:..." | "doc:..."
score: float = 1.0
source_ref 被设计为引用主键。SQL 证据生成 sql:...,文档证据生成 doc:{doc_name}#chunk{chunk_id}。合成阶段无需关心证据来源,只需引用 source_ref 即可。
4.4 AnswerPackage:交付结果与过程资产分离
最终返回的是 AnswerPackage,包含 trace_id + answer_text + citations + quality。运行过程(trace 事件、diagnostics)与交付结果(answer/citations)分离后,trace 更容易作为审计与回归资产沉淀。
@dataclass
class AnswerPackage:
trace_id: str
answer_text: str
citations: List[Citation] = field(default_factory=list)
quality: Optional[Diagnostics] = None
4.5 数据契约总结
TaskContext(统一输入)WorkerResult(统一输出,含诊断)EvidenceSet(在ctx.state中汇聚)AnswerPackage(统一交付结果,携带trace_id与citations)
该契约足够小,因此稳定。也足够明确,因此可扩展。
5. Worker 体系:统一接口与分工协作
本示例程序的 Worker 体系强调两点。能力边界显式化,输出形态统一化。编排层只关心调度顺序与证据汇聚,不被具体实现细节绑架。
5.1 统一接口与白名单:能力边界先于能力本身
Worker 抽象接口仅包含 name() 与 run(ctx)。
class Worker:
"""Worker 抽象接口。"""
def name(self) -> str:
"""返回注册表中的 worker 名称。
Returns:
worker 名称。
"""
raise NotImplementedError
def run(self, ctx: TaskContext) -> WorkerResult:
"""执行 worker 逻辑。
Args:
ctx: 任务上下文。
Returns:
WorkerResult 对象。
"""
raise NotImplementedError
注册表 WorkerRegistry 将“已注册”与“允许调度”分开处理。Controller 获取 Worker 时需同时满足两者,白名单因此成为系统级硬边界。
class WorkerRegistry:
"""Worker 注册表与白名单校验。"""
def is_allowed(self, name: str) -> bool:
"""检查 worker 是否在白名单内。
Args:
name: worker 名称。
Returns:
是否允许。
"""
return name in self._allowed
def get(self, name: str) -> Worker:
"""获取已注册且允许的 worker。
Args:
name: worker 名称。
Returns:
对应的 worker 实例。
"""
if name not in self._workers:
raise KeyError(f"Worker not registered: {name}")
if not self.is_allowed(name):
raise PermissionError(f"Worker not in allowlist: {name}")
return self._workers[name]
5.2 QueryRouterWorker:路由必须可解析,并且必须有兜底
路由目标是产出可执行的 RouteDecision(route=SQL|RAG|MIX)。实现上优先走 LLM 路由,并使用 response_format={"type":"json_object"} 约束输出形态。当模型输出为空、JSON 解析失败或 route 非法时,回退到关键词启发式路由,保证链路可用。
prompt = {
"task": "route_question",
"routes": ["SQL", "RAG", "MIX"],
"question": ctx.question.text,
"required_output": {
"route": "SQL|RAG|MIX",
"confidence": "0~1",
"rationale": "short reason"
}
}
out = self.llm.chat(
model=self.chat_model,
messages=[
{"role": "system", "content": "Output a single JSON object ONLY."},
{"role": "user", "content": json.dumps(prompt, ensure_ascii=False)},
],
thinking={"type": "disabled"},
# IMPORTANT: enforce valid JSON output per official API capability
response_format={"type": "json_object"},
temperature=0.0,
max_tokens=256,
)
# If model still returns empty, fall back immediately.
if not isinstance(out, str) or not out.strip():
rd = self._heuristic_route(ctx.question.text)
meta = {
"fallback": "empty_router_output",
"http_status": self.llm.last_status,
"url": self.llm.last_url,
"resp_preview": (self.llm.last_text_preview or "")[:600],
}
return WorkerResult(
status="ok",
route=rd,
diagnostics=Diagnostics(
"route_fallback",
"router empty; heuristic route used",
meta,
),
)
obj = _json_load_best_effort(out)
rd = RouteDecision(
route=str(obj.get("route", "RAG")).upper(),
confidence=float(obj.get("confidence", 0.6)),
rationale=str(obj.get("rationale", "")),
)
5.3 SQLWorker:LLM 只负责生成,执行前必须上锁
SQLWorker 的职责限定为生成 SQL、校验 SQL、执行只读查询并产出证据。需要强调的是,示例工程的校验属于基于字符串与正则的轻量规则约束,用于演示“最小可用的安全护栏”,并非完整 SQL 解析器。
关键校验逻辑如下。
def validate_sql(sql: str, allowed_tables: List[str], max_limit: int = 50) -> str:
"""校验 SQL 安全性并强制表名/限制规则。"""
s = sql.strip().rstrip(";")
if not re.match(r"^select\s", s, flags=re.I):
raise ValueError("Only SELECT statements are allowed")
if ";" in s:
raise ValueError("Multiple statements are not allowed")
tables = set()
for m in re.finditer(r"\b(from|join)\s+([a-zA-Z_][a-zA-Z0-9_]*)\b", s, flags=re.I):
tables.add(m.group(2))
allowed = {t.lower() for t in allowed_tables}
for t in tables:
if t.lower() not in allowed:
raise ValueError(f"Table not allowed: {t}")
m = re.search(r"\blimit\s+(\d+)\b", s, flags=re.I)
if m:
if int(m.group(1)) > max_limit:
raise ValueError(f"LIMIT too large (>{max_limit})")
return s
return f"{s} LIMIT {max_limit}"
生成—校验—执行—证据结构化的主流程如下。
out = self.llm.chat(
model=self.chat_model,
messages=[
{"role": "system", "content": "Return SQL only. No markdown. No explanation."},
{
"role": "system",
"content": (
"If a filter involves textual values, include both Chinese and "
"English variants with OR (e.g., status='进行中' OR status='ongoing')."
),
},
{
"role": "user",
"content": json.dumps(
{"question": ctx.question.text, "schema": schema},
ensure_ascii=False,
),
},
],
thinking={"type": "disabled"},
temperature=0.0,
max_tokens=256,
)
if not isinstance(out, str) or not out.strip():
raise ValueError("Empty SQL output")
sql = validate_sql(out.strip(), allowed_tables=self.allowed_tables, max_limit=50)
sql_ref = " ".join(sql.split())
cols, rows = self.db.run_select(sql)
md = _rows_to_md_table(cols, rows[:50])
ev = EvidenceSet(items=[
EvidenceItem(content=md, kind="sql", source_ref=f"sql:{sql_ref}", score=1.0)
])
5.4 RAGWorker:最小 RAG 的关键在于证据形态一致
文档检索由 SimpleVectorIndex 在启动期完成切块与批量向量化。查询阶段计算相似度取 TopK,并将结果标准化为 EvidenceItem(kind="doc"),以 source_ref=doc:{doc_name}#chunk{chunk_id} 作为引用主键。
hits = self.index.search(ctx.question.text, topk=self.topk)
if not hits:
return WorkerResult(
status="empty",
diagnostics=Diagnostics("rag_empty", "no doc evidence"),
)
items: List[EvidenceItem] = []
for ch, score in hits:
src = f"doc:{ch.doc_name}#chunk{ch.chunk_id}"
items.append(
EvidenceItem(
content=ch.text,
kind="doc",
source_ref=src,
score=float(score),
)
)
return WorkerResult(
status="ok",
evidence=EvidenceSet(items=items),
diagnostics=Diagnostics("rag_ok", "rag ok", {"hits": len(items)}),
)
5.5 SynthesisWorker:将“只基于证据”写成输出约束
合成阶段只读取 ctx.state["evidence"],证据为空则返回 empty。证据整理为带编号的文本块进入 prompt。指令要求每个事实句末尾携带 [doc:...] 或 [sql:...] 引用。引用通过正则抽取后写入 ctx.state["citations"],从而实现答案与引用清单的结构化分离。
evidence: EvidenceSet = ctx.state.get("evidence", EvidenceSet())
if not evidence.items:
return WorkerResult(status="empty", diagnostics=Diagnostics("syn_empty", "no evidence"))
ev_lines = []
for i, it in enumerate(evidence.items[:10], start=1):
ev_lines.append(f"[{i}] source_ref={it.source_ref} score={it.score:.3f}\n{it.content}")
out = self.llm.chat(
model=self.chat_model,
messages=[
{
"role": "system",
"content": "Output the final answer only. Use evidence only.",
},
{"role": "user", "content": json.dumps(prompt, ensure_ascii=False)},
],
thinking={"type": "disabled"},
temperature=0.2,
max_tokens=768,
)
cites = sorted(set(re.findall(r"\[(doc:[^\]]+|sql:[^\]]+)\]", out)))
ctx.state["citations"] = cites
6. Controller:编排(Orchestration)才是“智能体落地”的关键
Controller 的价值不在于“更聪明”,而在于将智能体从一次性对话变成可执行、可复盘的流水线。编排层负责决定调用顺序、管理中间态,并产出可追踪结果。能力在 Worker 内部实现,Controller 不替 Worker 做判断,也不替 Worker 做工作。
6.1 固定骨架:route → evidence → synthesis
固定骨架的目的,是将一次请求的执行语义压缩为三个清晰阶段,并把阶段间的“交接物”固化为数据契约。Controller 的工作因此收敛为三件事:拿到 route 决策、汇聚 evidence、触发 synthesis 并交付产物。能力实现细节留在 Worker 内部,编排层只负责顺序、分支与状态落点。
6.1.1 route:得到“可执行分支条件”,并固化到 trace
route 阶段的产物不是一段解释,而是一个可直接驱动分支的决策对象。Controller 读取 WorkerResult.route,并把其关键字段写入 trace,保证后续排障时可以回答两个问题:本次为何选择该链路,以及该选择是否来自回退路径。
# 1) route
router = self.registry.get("QueryRouterWorker")
r = router.run(ctx)
rd = r.route
self.trace.record(
"route",
{
"route": rd.route,
"confidence": rd.confidence,
"rationale": rd.rationale,
"diag": (r.diagnostics.meta if r.diagnostics else {}),
},
)
此处的“固定”体现在两点。
- route 只允许进入有限集合(SQL/RAG/MIX),从而使 Controller 的分支穷尽且可测试。
- route 被记录为事件,而不是隐藏在模型输出中,成为后续回放与回归的入口点。
6.1.2 evidence:按 route 调度取证链路,并把多源证据汇聚为单一集合
evidence 阶段只做“取证与汇聚”,不做解释与生成。Controller 根据 rd.route 调度 SQLWorker、RAGWorker 或两者,并将两路结果统一追加到同一个 EvidenceSet。MIX 的语义也在这里被固定为“双路取证必执行 + 证据合并”,避免在不同问题上出现执行语义漂移。
# 2) evidence
evidence = EvidenceSet()
if rd.route in ("SQL", "MIX"):
sqlw = self.registry.get("SQLWorker")
sr = sqlw.run(ctx)
self.trace.record(
"sql",
{
"status": sr.status,
"diag": (sr.diagnostics.meta if sr.diagnostics else {}),
"msg": (sr.diagnostics.message if sr.diagnostics else ""),
},
)
if sr.evidence:
evidence.extend(sr.evidence)
if rd.route in ("RAG", "MIX"):
ragw = self.registry.get("RAGWorker")
rr = ragw.run(ctx)
self.trace.record(
"rag",
{
"status": rr.status,
"diag": (rr.diagnostics.meta if rr.diagnostics else {}),
"msg": (rr.diagnostics.message if rr.diagnostics else ""),
},
)
if rr.evidence:
evidence.extend(rr.evidence)
在证据汇聚完成后,Controller 做两件关键的“边界动作”。
- 将证据集写入
ctx.state["evidence"],作为 synthesis 的唯一输入来源。 - 记录证据规模,使“证据是否缺失、何处缺失”可被 trace 直接观察。
ctx.state["evidence"] = evidence
self.trace.record("evidence", {"count": len(evidence.items)})
至此,evidence 阶段的职责被严格限定为:调度取证、合并证据、落入 state、写入 trace。任何生成式内容都不会在该阶段出现。
6.1.3 synthesis:只消费证据集生成答案,并将引用列表写入 state
synthesis 阶段的输入边界由上一阶段的 ctx.state["evidence"] 定义。Controller 触发 SynthesisWorker 执行,并将合成结果的状态与诊断写入 trace。Controller 不参与答案生成,也不拼接证据文本。
# 3) synthesis
syn = self.registry.get("SynthesisWorker")
ar = syn.run(ctx)
self.trace.record(
"synthesis",
{
"status": ar.status,
"diag": (ar.diagnostics.meta if ar.diagnostics else {}),
"msg": (ar.diagnostics.message if ar.diagnostics else ""),
},
)
引用链路的落点同样是 state。SynthesisWorker 在合成完成后,会把抽取到的引用写入 ctx.state["citations"],使 Controller 可以在组装交付物时将“答案”与“引用清单”分离处理,而无需解析答案正文。
注:synthesis 的“只基于证据”约束与引用抽取逻辑属于 Worker 内部实现,Controller 侧只约束输入边界(只从 state 取 evidence)与交付结构(从 state 取 citations)。
6.1.4 骨架的工程含义
route、evidence、synthesis 三段的固定化带来一个可验证的闭环。
- route 固定分支条件,使执行语义可穷举、可回放。
- evidence 固定中间产物形态,使多源信息可汇聚、可计量。
- synthesis 固定输入边界与引用落点,使答案可复核、可拆分交付。
因此,Controller/Worker 模式的“稳定性”并不来自更复杂的提示词,而来自编排骨架对分支、状态与产物的明确约束。
6.2 trace 事件:把“发生过什么”固化为事实
TraceRecorder 的事件结构极简,足以形成最小审计记录。Controller 只需以统一入口追加事件,无需让每个 Worker 自行处理落盘与格式化。
class TraceRecorder:
"""收集 trace 事件用于调试与审计。"""
def __init__(self) -> None:
self.events: List[dict] = []
def record(self, type_: str, data: dict) -> None:
"""追加一条 trace 事件。
Args:
type_: 事件类型标识。
data: 事件负载数据。
Returns:
None.
"""
self.events.append({"ts": time.time(), "type": type_, "data": data})
Controller 记录 route/sql/rag/synthesis 事件时,会将对应 Worker 的诊断信息写入事件负载:diag = WorkerResult.diagnostics.meta,同时写入 status/msg 等必要字段。因此排障时只需按时间顺序回看 trace,即可定位路由是否走回退、某一路取证是否为空或报错、证据汇聚后条数是否为 0。 外部调用线索(例如 HTTP 状态码、URL、响应预览)由 Worker 在构造 Diagnostics.meta 时填入,Controller 仅负责把这份 meta 统一写入 trace。
另外,Router 的 confidence 在提示词与输出契约中被约定为 0~1 的数值。实现侧会解析为 float 并记录到 trace,但并未对取值范围做强校验。若需要更严格的质量门槛,可在 Router 解析后加入范围校验或 clamp,并在 trace 中记录异常值。
6.3 中间态与产物:只保存必要共享,并负责落盘
证据写入 ctx.state["evidence"],引用写入 ctx.state["citations"],最终组装为 AnswerPackage 返回。产物由 ArtifactStore 负责持久化。answer.md 面向阅读,trace.json 面向调试与审计。
ArtifactStore 的写入逻辑集中在两个方法中,避免在 Controller 或 Worker 内散落 I/O 细节。
def write_answer(self, text: str, question: str | None = None) -> str:
"""把回答写入 answer.md。
Args:
text: 回答正文。
question: 原始问题(可选)。
Returns:
输出文件路径字符串。
"""
p = self.out_dir / "answer.md"
formatted = self._format_answer(text)
if question:
block = f"## 问题: {question}\n\n### 答案\n\n{formatted}\n"
else:
block = formatted + "\n"
if p.exists():
prefix = "\n---\n\n"
p.write_text(p.read_text(encoding="utf-8") + prefix + block, encoding="utf-8")
else:
p.write_text(block, encoding="utf-8")
return str(p)
def write_trace(self, events: List[dict]) -> str:
"""写入 trace 事件到 trace.json。
Args:
events: trace 事件列表。
Returns:
输出文件路径字符串。
"""
p = self.out_dir / "trace.json"
p.write_text(json.dumps(events, ensure_ascii=False, indent=2), encoding="utf-8")
return str(p)
6.4 失败策略:允许失败,但不允许“无产物失败”
模型输出为空并不被视为异常,而是必须被产品化处理的分支。Controller 在合成阶段后对答案做“空输出兜底”,并在任何情况下写入 answer.md 与 trace.json,保证排障闭环不被切断。
answer = ""
if ar.status == "ok":
answer = str(ar.data.get("answer", "") or "")
if not answer.strip():
answer = (
"(Empty model output)\n\n"
"请检查:1) ZHIPUAI_CHAT_MODEL 是否可用;2) ZHIPUAI_BASE_URL 是否正确;"
"3) API Key 是否有效;4) 将 DEBUG_LLM=1 后查看 trace 里的 "
"resp_preview / url / http_status。"
)
citations = [Citation(c) for c in ctx.state.get("citations", [])]
# artifacts
self.artifacts.write_answer(answer, question=question_text)
self.artifacts.write_trace(self.trace.events)
return AnswerPackage(
trace_id=trace_id,
answer_text=answer,
citations=citations,
quality=Diagnostics("ok", "done"),
)
7. LLM 接入层:为什么需要、带来什么收益、如何做最小封装
在 Controller/Worker 架构中,LLM 调用属于外部依赖。若将 HTTP 细节、鉴权、超时与响应解析分散到各个 Worker,维护成本会快速上升。供应商字段调整、输出结构变化、重试策略补充都需要多处同步修改。接入层的目标是将变化面收敛到单点,从而让业务链路保持稳定。
7.1 为什么需要接入层
接入层集中处理三类问题。
- 协议与鉴权:URL、请求头、JSON 编码、超时
- 响应规范化:上层只消费“文本”或“向量”,不关心响应细节
- 诊断与可观测:为空输出、非 200、非法 JSON 等场景的可定位性
7.2 接入层的优点
- 解耦:Worker 表达业务意图,不承载平台细节
- 一致性:统一超时、统一错误处理、统一响应提取
- 可演进:重试、退避、限流、代理、模型切换集中修改
7.3 最小封装示例:ZhipuHTTPClient(与源代码一致)
接入层以 ZhipuHTTPClient 形式存在。对上提供 chat() 与 embed() 两个业务友好方法。对下封装 _post(),集中处理 HTTP 调用细节与诊断字段。
核心请求片段如下(源代码连续片段)。
url = urljoin(self.base_url, path.lstrip("/"))
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json",
}
resp = requests.post(
url,
headers=headers,
data=json.dumps(payload, ensure_ascii=False).encode("utf-8"),
timeout=self.timeout_s,
)
self.last_url = url
self.last_status = resp.status_code
text = resp.text or ""
self.last_text_preview = text[:1200]
# 非 200 直接抛错,保留响应前 1200 字符便于排查
if resp.status_code != 200:
raise RuntimeError(f"HTTP {resp.status_code} calling {url}: {text[:1200]}")
try:
obj = resp.json()
except Exception:
raise RuntimeError(f"Invalid JSON response from {url}: {text[:1200]}")
if isinstance(obj, dict):
self.last_json = obj
return obj
对话封装片段如下(确保 payload.update(kwargs) 可透传平台参数)。
payload: Dict[str, Any] = {
"model": model,
"messages": messages,
"temperature": temperature,
"stream": False,
"max_tokens": int(max_tokens),
}
if thinking is not None:
payload["thinking"] = thinking
payload.update(kwargs)
obj = self._post("chat/completions", payload)
text = self._extract_text_from_obj(obj)
# 若仍为空,返回空字符串,但保留 last_json 便于追踪
return text or ""
向量封装片段如下。
payload: Dict[str, Any] = {
"model": model,
"input": inputs if len(inputs) > 1 else inputs[0],
}
if dimensions is not None:
# 向量维度需为整数
payload["dimensions"] = int(dimensions)
payload.update(kwargs)
obj = self._post("embeddings", payload)
data = obj.get("data") or []
if not isinstance(data, list):
return []
# 按 index 排序,保证输出顺序稳定
data_sorted = sorted(
[d for d in data if isinstance(d, dict)],
key=lambda x: int(x.get("index", 0)),
)
return [d.get("embedding", []) for d in data_sorted]
7.4 上层如何使用
接入层对上只暴露初始化点。启动时构建客户端并注入到 Worker 与向量索引中。
llm = ZhipuHTTPClient(api_key=api_key, base_url=base_url)
Worker 层只需调用 llm.chat(...) 与 llm.embed(...)。其余细节(鉴权、超时、响应解析、诊断字段)由接入层承担。
8. 扩展路线:从最小可运行到可上线
该工程的价值在于“结构完整且足够小”。扩展不需要推倒重来,而是沿着既有数据契约(TaskContext → WorkerResult → EvidenceSet → AnswerPackage)做增量增强。
8.1 Router 进化为 Planner:从选路到出计划
将 Router 升级为 Planner,输出受控 JSON 计划(步骤、输入引用、产物落点、并行组、停止条件)。Controller 保持骨架不变,取证阶段按计划执行。计划解析失败时回退到路由分支,保证可用性。
8.2 证据层增强:去重、冲突消解与裁剪
上线后常见问题不是“没证据”,而是“证据重复或冲突”。建议引入证据后处理,包括相似度去重、按可信度/版本/时间戳排序消解冲突,以及按预算裁剪证据集,避免合成阶段被噪声淹没。
8.3 并行执行:缩短延迟而不改变契约
MIX 路径下 SQL 与 RAG 可并行执行。输出仍以 WorkerResult 汇总,trace 补充分阶段耗时字段以支持性能回归。
8.4 工具型 Worker:外部系统能力纳入同一治理
将工单、CMDB、监控等系统能力按 Worker 粒度拆分,继续复用注册表白名单与字段校验,将权限与安全边界固化在代码路径中。
8.5 向量检索工程化:规模、增量与缓存
将内存索引替换为向量库。支持增量切块与增量写入。对 query embedding 与 topk 结果做缓存,并在知识版本变化时失效。
8.6 质量与回归:离线评测集 + 在线指标
沉淀典型问题评测集。基于 trace 统计 route 分布、空证据率、空答案率、证据条数、延迟、引用覆盖率等指标,形成可控上线的反馈闭环。
8.7 演进顺序建议
- Planner 与证据后处理
- MIX 并行化与耗时统计
- 工具型 Worker 接入与权限治理
- 向量库替换 + 增量索引 + 缓存
- 离线评测与在线指标面板(基于 trace)
9. 小结
本文以一个最小可运行工程为载体,将“子 Agent 调度”从概念落到可执行结构。Controller 固化编排骨架(路由—取证—合成),Workers 承担受控能力(SQL、RAG、综合)。证据作为中间产物被结构化为统一形态,trace 作为过程产物被固化为可回放的事件序列。系统输出不再依赖单次提示词的偶然稳定性,而由明确的流程与数据协议保障可复核性与可定位性。
核心方法可归纳为一条稳定的数据契约。TaskContext 作为统一输入,WorkerResult 作为统一输出,EvidenceSet 在上下文中汇聚,最终以 AnswerPackage 交付答案与引用。该契约足够小,因此易于保持稳定,也足够明确,因此便于扩展。在不破坏主骨架的前提下,后续可按需演进为 Planner 计划驱动、证据去重与冲突消解、并行取证、工具型 Worker 接入、向量库替换与增量索引,以及基于 trace 的质量评测与回归体系。
智能体落地的关键不在于模型能力的堆叠,而在于将模型置于一条可控、可观测、可回归的编排链路中。Controller/Worker 模式提供了实现该目标的最小而稳健的工程起点。
代码仓库:https://gitcode.com/gtyan/AgentHandBook/tree/main/06