

在真实业务中,“问一个问题”常常同时涉及结构化数据(客户、金额、时间窗口、Top N等)与非结构化知识(制度、手册、产品说明),再加上“本月/上周/今年”这类相对时间的天然歧义,仅靠检索增强生成(RAG)或仅靠NL2SQL都不足以支撑其实现。本文给出一套能跑的最小闭环:用SQLite多表存储企业数据;用智谱AI的embedding-3向量模型生成文本向量;用智谱AI的大语言模型将自然语言转换成单条只读的查询SQL并通过本地审计执行;最后基于“SQL查询结果+文档片段”进行证据约束生成。本文的示例代码还内置了相对时间解析(本月/上月/本周/上周/今年/去年/今天/昨天/前天),在进入检索和NL2SQL之前自动补齐明确的日期范围,避免模型对时间理解产生漂移。
0. 快速开始
首先可以从文末给出的代码仓库拉取代码,进行环境准备和配置后即可执行,体验其运行效果。
项目基于Python(Python 3.10+)语言实现,大模型使用智谱AI,依赖的包包括zhipuai(官方SDK)、numpy(向量计算)和python-dotenv(用于自动加载环境变量文件.env,无需手动export)。这些依赖已保存在requirements.txt文件中,可通过以下命令安装。
pip install -r requirements.txt
使用智谱AI需要配置其API Key,可将项目下的文件.env.example改名为.env,并将其中的ZHIPUAI_API_KEY设置为有效的API KEY。
# 必填
ZHIPUAI_API_KEY=替换为你的APIKey
# 可选
# ZHIPUAI_BASE_URL=https://open.bigmodel.cn/api/…
# ZHIPU_CHAT_MODEL=glm-4
# ZHIPU_EMBED_MODEL=embedding-3
# ZHIPU_EMBED_DIM=1024
完成依赖和配置后可直接启动程序进入对话模式。图 1、图 2、图 3分别展示了从文档中获取结果、从数据中获取结果、无相关信息时三种场景下的运行结果。

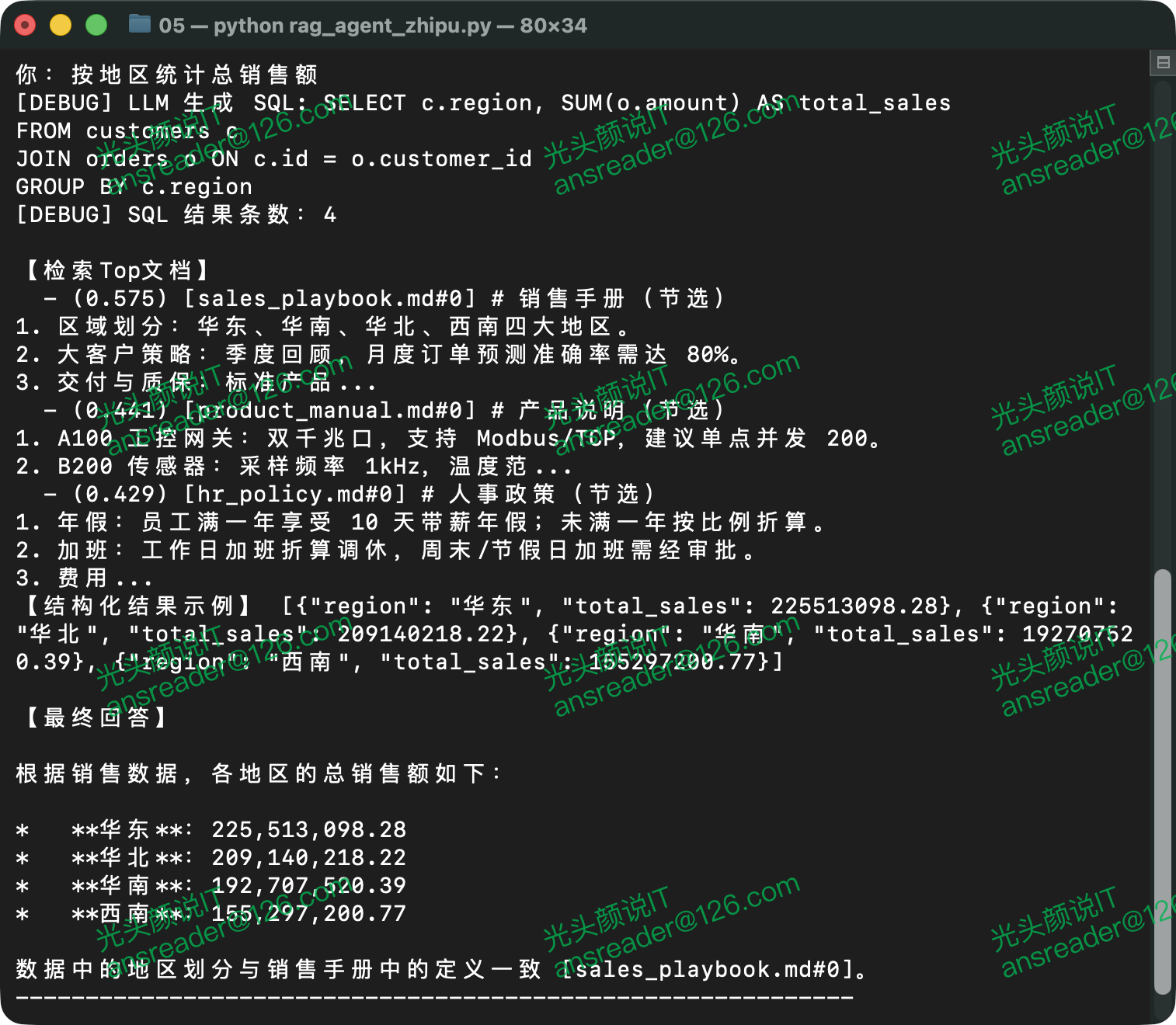
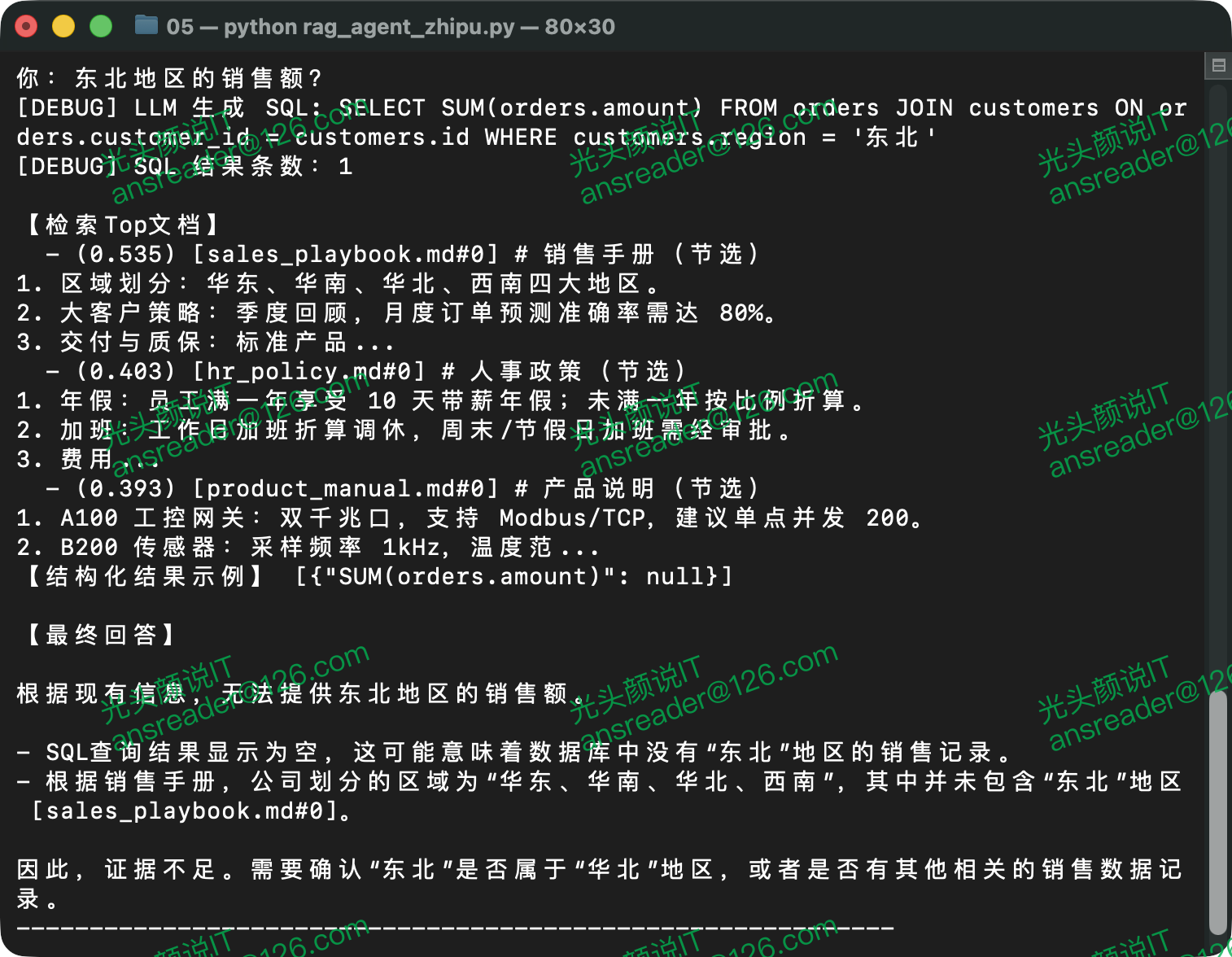
示例程序还支持更复杂的对话,例如图 4展示的对话需要先从数据库获取产品名,然后根据产品名从文档中查找其对应的质保期。

1. 为什么“企业数据+RAG+相对时间”要一起上?
在真实场景里,一个自然语言问题的答案往往同时触碰三类要素:一是结构化存储的事实(例如订单金额、客户分布、同比环比等,需要精确可计算);二是非结构化存储的规则等信息(例如质保条款、报销口径、销售政策等,需要从文档中找依据);三是时间语义(例如“本月”“上周”“去年”这类相对时间,需要明确的日期区间)。
如果只做其中的一块,往往不能对问题做出正确完整的响应:纯SQL/BI能算对数字,却解释不了政策;纯RAG能说清条款,却算不出报表;而不消解“相对时间”,模型所理解的时间或许与用户的期望相差千里。
把三者合在一条闭环里,目的不是堆功能,而是把不确定性逐段消解。先用“相对时间解析”把模糊时间转换成确定的时间窗口(例如“上月 → 2025-11-01~2025-11-30”),并把这个时间窗口绑定到用户问题,让检索与NL2SQL同步受益;再由NL2SQL生成单条只读SQL,经过本地审计(只允许SELECT、白名单表、禁危险关键字)后执行,确保所有数字都来自可追溯的结构化来源;最后将“SQL结果+文档片段”打包交给模型,让生成环节被证据约束,以便生成的最终回复是可信的。在把答案说明白的基础上,还可以选择将出处标出来(例如文档名称及页数等),使答案既可读又可核验。
这种组合还提供了“工程可观测性与可复现性”方面的价值。时间提示、检索命中、LLM生成的SQL、审计结论、查询结果,整个链路的中间态都能在控制台看见并复盘。当你觉得“模型有点玄学”时,可以先看时间解析是否生效、检索得分是否合理、SQL是否被严格约束,问题往往就明朗了。同样地,明确的日期区间让同一问题在不同时间或时区运行也更容易复现和对齐(例如周起于星期日/星期一的定义、UTC与本地时差等),而不是“今天能通过、明天就变样”。
再看业务视角:类似“上个月出售了哪些产品?它们的质保期分别是多久?”这样的问题,结构化与非结构化缺一不可。“上个月出售的产品”信息必须来自订单表,并且口径要对齐时间窗口;“质保期”则依赖产品手册与售后政策的具体条目。三者联动后,答案既给出产品信息,又能引用相关条款说明“为何这样判断”,把“答案是什么”与“凭什么答案是这样”同时交代清楚。
因此,“企业数据+ RAG + 相对时间”并不是三件散装配件,而是一条从“意图消歧”到“数据查询/计算”再到“证据表达”的紧凑流水线:时间增强减少误解,SQL审计防止越权与幻算,RAG引文提升可信度与可读性。结果就是更高的正确率、更少的幻觉、更清晰的溯源,并且通过跟踪提供了更低的调试成本与更快的迭代速度。
2. 模型与环境配置
模型与环境配置的目标是拿到模型与鉴权信息以及可能的默认值。本示例程序通过.env文件配置,程序启动时会用python-dotenv加载它(load_dotenv(find_dotenv(), override=False))。其中override的设定使得系统环境变量的优先级更高,如果同名变量已在系统环境中存在,.env中的变量值不会覆盖它。这既方便本地调试,也便于容器/CI持续集成。
.env文件的内容如上文所示。程序从.env读取关键配置与默认值的代码如下:
# 自动加载 .env(如果存在);不覆盖已存在的系统环境变量
load_dotenv(find_dotenv(), override=False)
ZHIPU_API_KEY = os.environ.get(“ZHIPUAI_API_KEY”)
if not ZHIPU_API_KEY:
raise RuntimeError(“请在 .env 中设置 ZHIPUAI_API_KEY,或设置系统环境变量”)
CHAT_MODEL = os.environ.get(“ZHIPU_CHAT_MODEL”, “glm-4.6”) # 可改为 glm-4-flash
EMBED_MODEL = os.environ.get(“ZHIPU_EMBED_MODEL”, “embedding-3”) # 可改 embedding-2
EMBED_DIM = int(os.environ.get(“ZHIPU_EMBED_DIM”, “1024”)) # embedding-3 可自定义维度
上述变量中最重要的是鉴权变量“ZHIPUAI_API_KEY”。如果没有提供,程序会直接抛出异常并中止。因此,在.env或系统环境里至少需要设置这个变量。
3. 数据与索引:SQLite 多表 + 文档切片 + 向量检索
作为知识型智能体,首先要解决“知识数据存储”问题。如前所述,本示例的数据同时包含两条数据通道——结构化通道与非结构化通道。结构化通道用一组SQLite表格(customers/orders)记录可计算事实,保证数字可追溯、口径可复现;非结构化通道则对人事政策、销售手册、产品说明做“分片”与“嵌入”,并保存在向量库中,为规则与条款提供可引用的文本依据。
3.1 多表 SQLite(customers / orders)
结构化数据在本示例中采用SQLite存储,其目标是得到一套最小却真实可用的业务锚点:客户、地区、产品、金额、日期。它既能支撑NL2SQL的查询、分组、聚合与时间窗口计算,也能与知识片段(政策、手册)在回答阶段对齐引用。
示例使用两张表,虚拟建模出最常见的客户信息与销售明细。
客户信息表的建表语句及字段含义如下。
— 客户信息表
CREATE TABLE customers(
id INTEGER PRIMARY KEY, — 客户主键(自增整数,便于 JOIN 与索引)
name TEXT, — 客户名称(示例使用中文企业名)
region TEXT — 客户所属区域(示例值:华东、华北、华南、西南)。
)
销售明细表的建表语句及字段含义如下:
— 销售明细表
CREATE TABLE orders(
id INTEGER PRIMARY KEY, — 订单主键
customer_id INTEGER, — 客户ID,外键,指向customers.id
product TEXT, — 产品/服务名称
amount REAL, — 订单金额
date TEXT, — 订单日期(以 ISO 8601(YYYY-MM-DD)字符串存储)
FOREIGN KEY(customer_id) REFERENCES customers(id) — 关系约束
)
对上述建表语句补充说明两点:在SQLite中建立关系约束时需要使用“PRAGMA foreign_keys=ON”才会强校验,本示例侧重查询与演示,因而对此不强制;订单日期date使用了TEXT类型,其原因是在SQLite中,strftime()等日期函数可以直接对ISO 8601字符串生效,其范围查询也能直接用“>”“<”等操作符按字典序正确比较,写法简洁,兼容性好。迁移到MySQL/PG时可改为DATE或TIMESTAMP等类型并保留相同语义。
示例数据的关键不在“真实”,而在“能覆盖典型问法”,因而数据生成方法与分布遵循三条原则:
1)足够长的时间跨度:覆盖18个月左右(近540天),便于支持“今年/去年/上月/本月/本周/上周”这类时间窗口;
2)足够的维度多样性:客户分布在多区域、产品多品类,避免查询时没有结果;
3)确定性随机:固定随机种子,输出可复现,便于调试与回归。
以下代码实现基于上述原则的数据构建:
customers = [
(1, “星辰科技”, “华东”),
(2, “海纳能源”, “华北”),
(3, “南风智造”, “华南”),
(4, “川岳电气”, “西南”),
(5, “凌云数码”, “华东”),
……
]
cur.executemany(“INSERT INTO customers VALUES (?, ?, ?)”, customers)
# 生成最近 ~540 天订单
rng = np.random.default_rng(42)
products = [“A100”, “B200”, “服务包”]
base = date.today() – timedelta(days=540)
rows, oid = [], 1
for _ in range(30000):
cust = int(rng.integers(1, 50))
prod = str(rng.choice(products))
amount = float(np.round(rng.uniform(2000, 50000), 2))
d = base + timedelta(days=int(rng.integers(0, 540)))
rows.append((oid, cust, prod, amount, d.iso8601() if hasattr(d, “iso8601”) else d.isoformat()))
oid += 1
cur.executemany(“INSERT INTO orders VALUES (?, ?, ?, ?, ?)”, rows)
上述生成数据代码的具体策略实现有以下几个要点:
1)区域差异:客户分布到不同大区,支撑诸如“华东本月 Top 3”的分组排名;
2)产品差异:三种产品并存,让“按产品/客户聚合”的问法更有意义;
3)金额区间:2000~50000的连续分布能产生明显的高低差,排序查询更有辨识度;
4)日期均匀:0~540天的均匀抽样覆盖所有时间窗口,确保“今年/上月/本周”等都有命中;
5)可复现:固定“random.default_rng(42)”,让示例程序的调试输出可“回放”。
3.2 文档切片与嵌入
文档切片(Chunking)、嵌入(Embedding)与存储的目的是将“文本变成可检索的知识资产”。其过程是先把原文档切成“可对齐的语义片段”,再用嵌入模型(向量模型)把片段映射到“向量空间”,最后用一组简单但稳定的“内存索引”(片段列表 + 向量矩阵)支撑Top-K检索与引用溯源。本示例程序中索引直接放在内存中,实际生产系统中应替换为FAISS/pgvector等企业级向量库。
1.切片
切片是实现语义理解颗粒度及可引用性的手段,其目标是使得文本片段足够短以集中语义,同时又不至于割裂上下文。示例采用“按段落累积”的朴素策略,控制每个文本片段约350字,同时保留“可引用元数据”(即文档名称doc_id与切片序号chunk_id)。
每个切片的信息通过Chunk数据类保存,其定义如下:
@dataclass
class Chunk:
# 文档分片元数据:所属文档 ID、片内序号、文本内容
doc_id: str
chunk_id: int
text: str
通常情况下,每个自然段落是语义紧密相关的内容,因而在对文本进行切片时,示例程序保持自然段落的完整性,即不会将一个自然段落切分到两个切片中。在以下代码默认按350作为每个切片的大致长度对传入的文本进行切片处理。
def chunk_text(text: str, max_len: int = 350) -> List[str]:
# 按段落拼接,保持语义完整度,直到接近 max_len 时换片
paras = [p.strip() for p in text.strip().split(“\n”) if p.strip()]
out, buf = [], “”
for p in paras:
if len(buf) + len(p) + 1 <= max_len:
buf = (buf + “\n” + p).strip()
else:
if buf:
out.append(buf)
buf = p
if buf:
out.append(buf)
return out
build_corpus()函数实现对文档内容的拆分,它遍历传入的多个文档内容,调用chunk_text()函数完成切片,并将切片结果作为函数返回值。其实现代码如下:
def build_corpus(docs: Dict[str, str]) -> List[Chunk]:
# 将多文档拆分为 Chunk 列表,保留文档 ID 与分片顺序,供后续向量化检索。
chunks: List[Chunk] = []
for doc_id, content in docs.items():
parts = chunk_text(content, 350)
for i, part in enumerate(parts):
# chunk_id 保留原文内顺序,方便引用
chunks.append(Chunk(doc_id=doc_id, chunk_id=i, text=part))
return chunks
上述代码实现中有如下设计要点:
1)切片长度设定为350字是经验值,通常它能覆盖“一个规则条目/配置段落”的信息量。若文档更密集,可将它降到 200–280,若文档更稀疏可升提到400–500。
2)片段“不重叠”,本示例中前后两个切片之间没有重叠文本,这可能造成召回时语义的丢失,在实际生产应用中,为防止命中率不足,可为同一文档的前后相邻切片加入20–30%的滑动重叠区域。
3)doc_id及chunk_id保存了文本来源及切片序号,它可作为“引用键”,在回答阶段用“[doc_id#chunk_id]”形式标注来源,实现了信息的“可核验”。
2.嵌入
嵌入是实现语义理解的关键环节,它把“词句段落的含义”投影到高维向量空间,使“语义相近”的文本在几何上彼此接近,从而支持后续的相似度检索与重排。在本示例程序里,片段嵌入与查询嵌入使用同一模型(默认 embedding-3),并在入库前做L2归一化,使余弦相似度可以直接用点积快速近似。没有这一步,后续“Top-K 命中是否真的语义相关”就会变得不稳定。
embed_texts()函数实现了嵌入,并返回归一化之后的向量。
ZHIPU_API_KEY = os.environ.get(“ZHIPUAI_API_KEY”)
if not ZHIPU_API_KEY:
raise RuntimeError(“请在 .env 中设置 ZHIPUAI_API_KEY,或设置系统环境变量”)
client = ZhipuAI(api_key=ZHIPU_API_KEY)
CHAT_MODEL = os.environ.get(“ZHIPU_CHAT_MODEL”, “glm-4.6”) # 可改为 glm-4-flash
EMBED_MODEL = os.environ.get(“ZHIPU_EMBED_MODEL”, “embedding-3”) # 可改 embedding-2
EMBED_DIM = int(os.environ.get(“ZHIPU_EMBED_DIM”, “1024”)) # embedding-3 可自定义维度
# EMBED_DIM 仅在 embedding-3 下生效,用于控制输出向量长度
def embed_texts(texts: List[str], batch_size: int = 64) -> np.ndarray:
# 调用 ZhipuAI 向量接口做批量向量化。embedding-3 支持自定义维度。
vecs: List[List[float]] = []
for i in range(0, len(texts), batch_size):
batch = texts[i:i+batch_size]
resp = client.embeddings.create(
model=EMBED_MODEL,
input=batch if len(batch) > 1 else batch[0],
**({“dimensions”: EMBED_DIM} if EMBED_MODEL == “embedding-3” else {})
)
# 接口输出格式:resp.data 每条对应一个 embedding
if hasattr(resp, “data”) and isinstance(resp.data, list):
for item in resp.data:
vecs.append(item.embedding)
else:
vecs.append(resp.data[0].embedding) # 兼容性处理
import numpy as _np
arr = _np.array(vecs, dtype=_np.float32)
norms = _np.linalg.norm(arr, axis=1, keepdims=True) + 1e-9
# 统一做 L2 归一化,便于余弦相似度检索
return arr / norms
从工程角度看,嵌入的三要素是“表示质量、维度与归一化”。表示质量决定了模型是否能把类似“报销”“费用补贴”“餐补”等近义表达拉到一起,把“上月/本月”等相似时态区分开来。维度(本示例程序默认1024)影响容量与判别力,维度太低可能“挤”在一起导致混淆,太高则增加存储和向量运算成本。归一化是稳定检索的保险丝,它去除了“向量长度”的干扰,让相似度主要受“方向”(也就是语义)影响。
上述代码实现中包含以下几个实践要点:
1)批量请求显著减少网络开销,设定“batch_size=64”是兼顾稳定性与吞吐量的设计。
2)仅当模型为embedding-3时才传dimensions,换其他嵌入模型(embedding-2)时不传此参数即可。在实际应用中如果采用其他嵌入模型,可根据实际情况设定或不设定dimensions的值。
3)归一化是检索稳定性的关键,它可以避免“长向量更像”的数值偏置,让相似度真正反映语义“方向”。
3.存储
示例程序使用两段内存结构存储文本向量相关数据:
1)chunks: List[Chunk]:片段数组,保存文本与元数据;
2)chunk_vecs: np.ndarray [num_chunks, dim]:与chunks一一对应的已归一化的向量矩阵。
在实际生产项目中,可按以下规则对存储进行迁移:
1)原文档:对象存储(OSS/S3/本地盘)按doc_id保存源文件,保留版本与哈希。
2)片段表:chunks(doc_id, chunk_id, text, section, version, sha256, created_at, …);
向量表(pgvector/FAISS/ES):embeddings(doc_id, chunk_id, vector, dim, model, created_at, …);
3)一致性约束:(doc_id, chunk_id)作为联合主键,与回答引用规范“[doc_id#chunk_id]”对齐。
4. 相对时间增强:把“本月/上周/今年”变成显式日期范围
自然语言里的“本月、上周、今年、昨天”等相对时间于人类而言是简单、直观、易理解的时间概念,但对检索与SQL来说却是未明确的参数。示例程序在进入检索与NL2SQL之前,先对问题做一次“非侵入式增强”:识别相对时间词,计算出“明确的日期范围”,并以“提示”的方式拼回原问题,让两条通道共享同一时间口径,从而降低时间理解漂移。
相对时间增强首先实现对常见别名的归一映射,不同时间单位的常见别名整理如下,并可继续扩充:
1)月:{本月/这个月/当月}、{上月/上个月/上一个月}
2)周:{本周/这周/本星期}、{上周/上星期}
3)年:{今年/本年}、{去年}
4)日:{今天/今日}、{昨天/昨日}、{前天}
如果相对时间命中,则将其统一映射到标准标签(本月/上月/本周/上周/今年/去年/今天/昨天/前天),进入日期计算。
一般情况下涉及日期窗口的时间单位是“月”或者“周”,_month_range()函数与_week_range()函数分别实现了它们的日期窗口计算,并返回月或周的“闭区间”端点,为相对时间增强提供支持。其实现代码如下:
def _month_range(reference: date, offset: int = 0) -> Tuple[date, date]:
# 计算 reference 所在月的前/后 offset 个月的起止日期
year = reference.year
month = reference.month + offset
while month <= 0:
month += 12
year -= 1
while month > 12:
month -= 12
year += 1
start = date(year, month, 1)
end = date(year, month, calendar.monthrange(year, month)[1])
return start, end
def _week_range(reference: date, offset: int = 0) -> Tuple[date, date]:
# 计算 reference 所在周(周一至周日)相对位移 offset 后的起止日期
start = reference – timedelta(days=reference.weekday()) + timedelta(weeks=offset)
end = start + timedelta(days=6)
return start, end
基于上述工具对月、周的处理,结合“今年/去年”意指当年/上一年的“首末日”“今天/昨天/前天”使用“同一天”作为日期的起止规则,可实现完整的相对时间增强逻辑,其代码如下:
def augment_question_with_time_hint(question: str) -> Tuple[str, List[str]]:
“””为包含本月/上月/本周等相对时间的问题补充明确的日期范围,降低 LLM 误判。”””
today = date.today()
hints: Dict[str, Tuple[date, date]] = {}
patterns = [
({“本月”, “这个月”, “当月”}, lambda t: (“本月”, *_month_range(t, 0))),
({“上月”, “上个月”, “上一个月”}, lambda t: (“上月”, *_month_range(t, -1))),
({“本周”, “这周”, “本星期”}, lambda t: (“本周”, *_week_range(t, 0))),
({“上周”, “上星期”}, lambda t: (“上周”, *_week_range(t, -1))),
({“今年”, “本年”}, lambda t: (“今年”, date(t.year, 1, 1), date(t.year, 12, 31))),
({“去年”}, lambda t: (“去年”, date(t.year – 1, 1, 1), date(t.year – 1, 12, 31))),
({“今天”, “今日”}, lambda t: (“今天”, t, t)),
({“昨天”, “昨日”}, lambda t: (“昨天”, t – timedelta(days=1), t – timedelta(days=1))),
({“前天”}, lambda t: (“前天”, t – timedelta(days=2), t – timedelta(days=2))),
]
for keywords, fn in patterns:
if any(k in question for k in keywords):
label, start, end = fn(today)
hints.setdefault(label, (start, end))
if not hints:
return question, []
parts = []
for label, (start, end) in hints.items():
if start == end:
parts.append(f”{label}={start.isoformat()}”)
else:
parts.append(f”{label}={start.isoformat()}~{end.isoformat()}”)
hint_text = “;”.join(parts)
return f”{question}(时间范围提示:{hint_text})”, parts
在上述实现中使用“date.today()”获取当前日期,它以系统本地日期为准,若示例程序运行容器时间是UTC或其他特定时区,需要在部署侧固定业务时区或者修改代码取得特定时区日期,以避免跨天/跨周边界偏差现象。
当命中相对时间词时,函数会把“友好的相对时间自然语言提示”附回原问题;未命中则原样返回。输出格式遵循两种形态:
1)单日:标签=YYYY-MM-DD(如:“今天=2025-12-11”)
2)日期段:标签=YYYY-MM-DD~YYYY-MM-DD(如:“上月=2025-11-01~2025-11-30”)
相对时间增强实现后,可在向量检索、NL2SQL及答案综合三个时点使用。这意味着“时间范围提示”既能作为检索的语义扩展(常可提升 Top-K 命中),也能帮助NL2SQL更稳定地生成形如“date >= ‘YYYY-MM-DD’ AND date <= ‘YYYY-MM-DD’”的闭区间条件(注意:本实现并不直接拼接SQL,而是把提示交由模型理解与使用)。
例如,用户输入的原始提示是“华东上月销售额Top 3客户”相对时间增强后的提示则为“华东上月销售额Top 3客户(时间范围提示:上月=2025-11-01~2025-11-30)”,后续检索与NL2SQL都将基于增强后的问句执行。
在具体应用中,还可考虑以下可配置点与建议:
1)周起点若需从周日开始,可将_week_range()中的weekday()处理改为以周日为0的逻辑。
2)若希望统一为“半开区间”(便于SQL写“>= start AND < next_day(end)”),可在上述函数中调整end的取法。与当前闭区间表达相比,这是风格选择,不是对错问题。
3)业务常见词可在patterns中持续扩充(如“本季度/上季度/本财年”等),生成方式与月/年类似。
4)如需让“时间提示”在日志中更可视,可在交互环节打印q_with_time或time_hints。
5. NL2SQL:只输出一条SELECT
NL2SQL即将自然语言转换为SQL是查询关系数据库的关键环节,基于数据安全的原因,当前应用中通常仅允许查询数据。在具体实现上则是引导大模型只产出“单条只读SELECT语句”,并对产出的SQL进行安全审计再执行。在此过程中还要与“相对时间增强”联动——增强后的信息被送入NL2SQL,使模型更稳定地产生带时间约束的查询。
5.1 提示词约束:只许 SELECT、只查白名单表、只输出代码块
示例程序把数据库表结构与约束写进了System提示词,明确要求“只输出一段 `sql … ` 代码块且只能用两张表”。
SCHEMA_TEXT = “””– 数据库表结构
TABLE customers(id INTEGER PRIMARY KEY, name TEXT, region TEXT);
TABLE orders(id INTEGER PRIMARY KEY, customer_id INTEGER, product TEXT, amount REAL, date TEXT);
— 字段含义:
— customers.id:客户主键;customers.name:客户名称;customers.region:客户所属大区,仅存储“华东/华南/华北/西南”等简洁大区名,不含“大区”“地区”字样。
— orders.id:订单主键;orders.customer_id:关联的客户 ID;orders.product:产品型号/类型;
— orders.amount:订单金额(元);orders.date:订单日期(ISO 格式字符串)。
— 关系:
— orders.customer_id -> customers.id
— 仅允许只读 SELECT,不允许 INSERT/UPDATE/DELETE/DDL;不允许多条语句;不允许子查询以外的 ; 号。
“””
SQL_SYSTEM_PROMPT = f”””# 角色
你是一个严谨的企业数据分析助手。你的核心任务是**识别用户的查询意图**,并**仅在意图与数据库无关时拒绝查询**。
# 工作流程与判断标准
你必须严格遵循以下逻辑:
## 步骤 1:明确拒绝
首先,检查用户问题是否属于以下**完全无关**的类别。如果是,**必须且仅输出 `NO_SQL`**。
– **无关对话**:打招呼、问候、闲聊(如“你好”、“谢谢”、“在吗?”)。
– **元问题**:询问关于你自身、系统或规则的问题(如“你是谁?”、“你能做什么?”)。
– **纯知识问答**:与数据库数据无关的通用知识或技术问题(如“什么是SQL?”、“华东地区包括哪些省份?”)。
## 步骤 2:数据关联性判断
如果问题不属于上述类别,则进一步判断:**问题是否意图查询 `customers` 或 `orders` 表中的任何实体信息?**
– **实体信息包括**:客户、订单、产品、金额、日期、区域、数量、排名等。
– **关键原则**:**只要问题中提到了与数据库实体相关的关键词(如“最近一个订单”、“销售额最高的产品”、“华北的客户”),即使它询问的属性(如“质保期”、“联系方式”、“库存”)在数据库中不存在,也**必须**被视为与数据相关,并进入下一步生成 SQL。**
## 步骤 3:SQL 生成
如果步骤 2 的判断是“与数据相关”,则根据以下规则生成单条 SQL 语句。
### 生成规则
– **核心任务**:你的任务是查询数据库,以定位问题中提到的核心实体(如“最近一个订单”、“销售额最高的产品”)。
– **表与字段**:仅使用 `customers` 和 `orders` 表,且字段名必须来自 Schema。不得臆造字段名。
– **查询类型**:只能生成单条 `SELECT` 语句。严禁 `INSERT`, `UPDATE`, `DELETE`, `DDL`以及任何形式的注释。
– **语句格式**:禁止以分号 `;` 结尾。
– **字段选择**:显式列出所需字段,避免使用 `SELECT *`。
– **聚合与排序**:如需回答“最新/最近/最后/最多/最少”等问题,必须使用完整的 `ORDER BY` 和 `LIMIT` 子句。时间相关的排序基于 `orders.date` 字段。
– **时间范围**:如果用户消息包含“时间范围提示:xxx~yyy”,必须使用 `orders.date` 进行精确过滤。
– **数据特性**:`customers.region` 字段仅存储“华东”、“华南”等简洁大区名,不含“大区”等后缀。
# 上下文
当前日期:{date.today().isoformat()}
{SCHEMA_TEXT}
# 输出格式
– 如果问题完全无关,仅输出 `NO_SQL`。
– 如果问题与数据库实体相关,只输出 SQL 语句,并将其包裹在 “`sql … “` 代码块中。
“””
上述System提示词中说明表结构时同步说明各个字段的含义,这对于大模型理解表结构非常重要,建议在落地项目中使用语义明确的字段名,同时对字段含义及相关信息进行说明。
5.2 生成与解析:只取SQL代码块内容
llm_nl2sql()函数调用对话模型生成SQL或者取得当前问题不需要SQL的结论,在生成SQL的情况下用正则仅提取`sql … `块内的文本,避免“解释+SQL混杂”而干扰后继流程。
def llm_nl2sql(question: str) -> Optional[str]:
# 交给 GLM 生成 SQL,再从代码块中抽取裸 SQL 字符串
messages = [
{“role”: “system”, “content”: SQL_SYSTEM_PROMPT},
{“role”: “user”, “content”: question}
]
resp = client.chat.completions.create(
model=CHAT_MODEL,
messages=messages,
temperature=0.2,
)
text = resp.choices[0].message.content or “”
if “NO_SQL” in text.upper():
return None
m = re.search(r”“`sql\s*(.*?)\s*“`”, text, re.S | re.I)
sql = m.group(1).strip() if m else text.strip()
return sql or None
上述代码在调用大模型时选择了较低的温度,以提升大模型响应的稳定性。如果模型响应发生意外未使用代码块包装SQL,则会回退为整段文本(随后仍会进入审计)。此外,使用函数参数传入问题时,应通过相对时间增强包含“时间范围提示”,以便帮助模型在WHERE中产生正确的时间条件。
5.3 本地安全审计:起始关键字 + 黑名单 + 表白名单
生成SQL之后,先走审计,不通过就不执行。当前实现覆盖三类检查,即仅允许SELECT查询、检测危险关键字及可访问的表。
ALLOWED_TABLES = {“customers”, “orders”}
def audit_sql(sql: str) -> Optional[str]:
s = sql.strip().rstrip(“;”)
if not re.match(r”(?is)^\s*select\b”, s):
return “仅允许 SELECT 查询”
banned = [“insert”, “update”, “delete”, “drop”, “pragma”, “attach”, “alter”, “create”, “grant”, “reindex”, “;–“, “/*”, “*/”]
# 粗粒度黑名单 + 表名白名单拦截,避免误执行危险语句
if any(b in s.lower() for b in banned):
return “检测到危险关键字或注释”
tokens = re.findall(r”\b(from|join)\s+([a-zA-Z_][a-zA-Z0-9_]*)”, s, re.I)
for _, t in tokens:
if t.lower() not in ALLOWED_TABLES:
return f”不允许访问表:{t}”
return None # 通过
当前审计并未“语法级”验证“多语句/注释穿插”等复杂情形(主要依赖提示词去抑制)。若担心极端对抗样例,建议在生产项目用AST/解析器做“单语句/只读”强校验,并对分号(;)的出现位置、字符串字面量等边界做更严谨处理。
5.4 执行与结果:只读查询、字典化返回
审计通过后调用SQLite执行,并把“Row”转成“dict”,方便后续JSON序列化给答案综合模块。
def run_sql(sql: str) -> List[Dict[str, Any]]:
# 仅执行 SELECT;返回 [{列: 值}, …]
conn = sqlite3.connect(DB_PATH)
conn.row_factory = sqlite3.Row
cur = conn.cursor()
cur.execute(sql)
rows = [dict(r) for r in cur.fetchall()]
conn.close()
return rows
5.5 端到端路径:时间增强 → NL2SQL → 审计 → 执行
在NL2SQL的端到端的处理链路中,首先对用户原始问题做“相对时间增强”。augment_question_with_time_hint(q)会识别诸如“本月/上周/今年/昨天”等相对时间表达,计算出明确的日期范围,并以“时间范围提示:…”的自然语言形式附回问题本身,得到q_with_time。这样做的目的是减少时间边界理解漂移。
随后进入NL2SQL。系统提示词明确约束“只生成单条只读SELECT,并仅访问customers与 orders两张表,且将SQL放入`sql` 代码块”。在此约束下,以q_with_time作为用户消息调用llm_nl2sql(),并解析出大模型生成代码块中的SQL文本。得到候选SQL后,不应直接执行,而是先进行本地安全审计,audit_sql(sql)将检查SQL语句是否以SELECT开头、是否含写操作/DDL/注释等危险关键字,以及FROM/JOIN是否仅落在白名单表内。若审计失败,会在控制台打印“WARN”并终止执行,保证安全优先;通过审计则进入只读查询阶段。
最后,由run_sql(sql)在SQLite上执行查询,结果以列表字典的形式返回,便于后续JSON化并与检索到的文档片段一起交给答案综合模块。整条链路中的关键中间态(增强后的问题、模型生成的 SQL、审计结论、返回记录条数)都会以DEBUG/WARN的形式输出到控制台,便于快速复盘与定位,当答案异常时,可以回溯看到时间提示是否生效、SQL是否被严格约束,以及结构化侧究竟返回了什么。
5.6 常见问题与定位
1.模型返回两段SQL/SQL外带解释
优先检查提示词是否“只输出 `sql` 代码块”描述足够明确;当前解析已优先提取代码块,若仍失败,增补few-shot(“问法 → 正确 SQL”)可显著改善。
2.审计误杀/漏杀
1)误杀:例如字段名/表别名大小写问题,可在正则与白名单处放宽大小写;
2)漏杀:极端情况下可混入 `;` 或注释规避黑名单,生产建议上AST解析、单语句校验与只读账户。
3.时间条件不稳定
1)先看输入是否带有“时间范围提示”;没有则是未命中时间关键词;
2)有提示但SQL不采用,可加few-shot强化,或在System中强调“若出现‘时间范围提示’,请据此构造 `WHERE` 条件”。
4.聚合/排序口径不一致
NL2SQL易在GROUP BY/ORDER BY等细节上波动,可通过few-shot约束“TopN的写法”“按金额降序”“按地区分组”等,稳定性会提升一个量级。
6. 文档侧:向量检索 + 调试友好的 Top-K 打印
文档检索在本示例中使用“单塔嵌入 → 余弦近邻 → Top-K 命中回显”的经典路径。先在启动阶段把所有片段做嵌入并L2归一化缓存成矩阵chunk_vecs,查询时再把“增强后的问题”q_with_time向量化,与矩阵做一次向量点积得到相似度分数,取Top-K返回(分数越高语义越近)。主循环会把Top-K 的分数、引用键与片段摘要打印出来,便于快速判断“命中是否符合直觉”。
文档检索由topk_by_embedding()函数完成,其代码如下:
def topk_by_embedding(
query: str,
chunk_vecs: np.ndarray,
chunks: List[Chunk],
k: int = 4,
) -> List[Tuple[float, Chunk]]:
# 对查询句向量化并与缓存向量矩阵做内积,返回相似度 Top-K
q = client.embeddings.create(
model=EMBED_MODEL,
input=query,
**({“dimensions”: EMBED_DIM} if EMBED_MODEL == “embedding-3” else {})
)
import numpy as _np
qv = _np.array(q.data[0].embedding, dtype=_np.float32)
qv = qv / (_np.linalg.norm(qv) + 1e-9)
sims = chunk_vecs @ qv
idx = _np.argsort(-sims)[:k]
return [(float(sims[i]), chunks[i]) for i in idx]
上述检索函数与片段嵌入使用了同一嵌入模型,并且也同样进行L2归一化处理,以保证检索也在归一化的向量上进行。
文档检索函数topk_by_embedding()也在主循环中被调用,且直接使用q_with_time,因而“时间范围提示”也参与了嵌入语义,从而在低样本语境下提升命中质量。
doc_hits = topk_by_embedding(q_with_time, chunk_vecs, chunks, k=4)
通过嵌入实现文档与查询时有以下要点要特别注意:
1)归一化不可省:片段矩阵chunk_vecs在预处理时已经做过L2归一化;查询向量也要做L2归一化。这样“sims = chunk_vecs @ qv”就是标准余弦分数,避免“长向量更占便宜”的长度偏置。
2)k 的选择:默认“k=4”足以支撑大多数生成场景;若文档段落更零散或答案需要跨段引用,可以把k提到6~8再在合成阶段做内容去冗。
3)分数分布的“温度计”:Top1明显高于Top2/Top3,且绝对值≥0.45,通常意味着问法与切片都较匹配;若整体挤在0.20~0.30,优先考虑两种手段:其一,扩写查询(例如继续依赖“时间范围提示”、补充地区/产品等关键词);其二,调整切片长度(过长会稀释主题词,过短容易丢上下文)。
4)缓存与成本:片段嵌入是静态的,建议在构建时一次性生成并持久化(本示例程序以内存矩阵演示);查询嵌入可以对高频问题做短期缓存,降低反复调用的成本。
5)一致性:不要混用不同嵌入模型/维度的向量。若更换嵌入模型或向量维度,需要整库重新嵌入,并在元数据里记录“model/dim/version”,避免“新旧向量混检”。
7. 证据约束生成:把“SQL 结果 + 文档片段”打包成 JSON 再让大模型作答
证据约束生成的目标是让模型只基于可验证证据作答,避免其“凭印象发挥”。具体做法是把三类关键信息打包成结构化JSON:一是增强后的用户问题(q_with_time,含“时间范围提示”);二是经审计并执行得到的结构化结果(sql_rows);三是向量检索得到的文档片段(doc_hits,带可回溯引用键)。随后以固定的System约束提示模型只能够依据证据回答并在需要时标注引用。这样既能让回答“言之有物”,又能把“凭什么这么说”直接暴露给读者与调试者。
在代码中,上述逻辑由synthesize_with_llm()函数实现。它首先会把输入整理为一个稳定的JSON负载:question为增强后的问句,sql_rows截取前 10 行用于生成(避免把整表大量搬给模型影响稳定性与成本),doc_snippets则从检索Top-K中取前4条片段并转换为“{ref, text}”形式的轻量对象,其中ref采用统一的“[doc_id#chunk_id]”形式,text为片段正文的裁切版。随后以低温度调用大模型。
synthesize_with_llm()函数的代码如下:
ANSWER_SYSTEM = “””你是企业知识问答助手。
请仅依据“SQL结果”和“文档片段”作答,必要时给出简短解释。
– 引用文档时使用 [doc_id#chunk_id] 形式。
– 如果证据不足,明确说明不足并给出需要的补充信息。”””
def synthesize_with_llm(question: str,
sql_rows: List[Dict[str, Any]],
doc_hits: List[Tuple[float, ‘Chunk’]],
generated_sql: Optional[str] = None
) -> str:
# 将 SQL 结果与文档片段打包成 JSON 传入 LLM,指导其引用证据作答
sql_preview = json.dumps(sql_rows[:10], ensure_ascii=False)
doc_preview = [
{“ref”: f”{c.doc_id}#{c.chunk_id}”, “text”: c.text.strip()} for _, c in doc_hits[:4]
]
payload = {
“question”: question,
“sql_rows”: json.loads(sql_preview),
“doc_snippets”: doc_preview
}
if generated_sql:
payload[“generated_sql”] = generated_sql
messages = [
{“role”: “system”, “content”: ANSWER_SYSTEM},
{“role”: “user”, “content”: json.dumps(payload, ensure_ascii=False)}
]
resp = client.chat.completions.create(
model=CHAT_MODEL,
messages=messages,
temperature=0.2,
)
return resp.choices[0].message.content or “”
synthesize_with_llm()在生成最终答案时,也提供了将生成SQL语句传入的可选参数,在通过生成SQL取得数据的场景下,同步提供SQL指令将有助于大模型更好地理解数据。事实上,这也是在为大模型提供上下文信息。
8. 示例交互与“相对时间”实战
完成数据准备及查询结构化数据与非结构化数据、最终答案生成等各项工作后,就可以将它们组织起来,形成一个知识型智能体。调用组织这些模块的逻辑在main()函数中完成。
main()函数的实现流程可以分为“启动初始化”和“循环交互”两段。启动阶段先完成环境与底座准备,即创建/填充最小业务库(调用ensure_sqlite_db()建好customers与orders两张表并构建数据),构建知识语料(将人事政策、销售手册、产品说明读入后用build_corpus()切片),然后调用embed_texts()对所有片段批量向量化并做L2归一化处理得到与chunks一一对应的矩阵chunk_vecs。初始化完成后打印就绪提示与示例问题,进入交互循环。
每一轮交互从读取用户输入开始;若输入为“exit/quit”则优雅退出。否则对问题先做一次“相对时间增强”——augment_question_with_time_hint()识别“本月/上月/本周/上周/今年/去年/今天/昨天/前天”等表达,计算日期范围并以“(时间范围提示:…)”自然语言附回原问题,输出增强后的q_with_time。接着按“检索 → NL2SQL → 审计/执行 → 合成”的顺序推进:首先以q_with_time调用topk_by_embedding(q_with_time, chunk_vecs, chunks, k=4)做向量检索,得到带相似度分数与“[doc_id#chunk_id]”的doc_hits;然后以q_with_time交给llm_nl2sql(),在严格的System提示词约束下由大模型生成一条只读SELECT;得到候选SQL后先通过audit_sql()函数进行本地安全审计(只允许SELECT开头、黑名单过滤危险关键字、FROM/JOIN限定在customers/orders白名单),如果未通过则给出告警并跳过执行,通过则用run_sql()在SQLite上只读查询并将结果行转成List[dict]。最后调用synthesize_with_llm()使用增强后的问题、结构化sql_rows与文档片段doc_hits进行答案合成,并将“最终回答”按固定格式打印出来。
上述过程中如果出现异常则输出WARN日志以便快速定位到底是时间增强未命中、检索不相关、NL2SQL不稳定还是审计/执行失败。整套流程在同一轮中闭环运行,随后继续等待下一条用户输入。
main()函数的代码如下:
# ====== 交互主流程 ======
def main():
print(“== 初始化数据与索引 ==”)
ensure_sqlite_db(DB_PATH)
print(“构建文档分片…”)
chunks = build_corpus(DOCS)
print(f”分片数:{len(chunks)}”)
print(f”向量化({EMBED_MODEL}, dim={EMBED_DIM})…”)
chunk_vecs = embed_texts([c.text for c in chunks])
print(“就绪。示例:”)
print(” – 星辰科技2024年订单总额”)
print(” – 华东地区上月销售额Top 3客户”)
print(” – 按地区统计今年销售额”)
print(” – A100的质保多久?”)
print(” – 出差住宿与餐补标准是什么?”)
print(“输入 exit 或 quit 结束。\n”)
while True:
q = input(“你:”).strip()
if q.lower() in (“exit”, “quit”, “q”):
print(“再见!”)
break
q_with_time, time_hints = augment_question_with_time_hint(q)
if time_hints:
print(f”[DEBUG] 解析相对时间:{‘;’.join(time_hints)}”)
# 1) 文档检索
doc_hits = topk_by_embedding(q_with_time, chunk_vecs, chunks, k=4)
# 2) NL2SQL + 审计 + 查询(失败则空列表)
sql_rows: List[Dict[str, Any]] = []
generated_sql: Optional[str] = None
try:
# 由 LLM 判断是否需要 SQL;若返回 None 表示无需结构化查询
generated_sql = llm_nl2sql(q_with_time)
if not generated_sql:
print(“[DEBUG] 略过 SQL 生成(判断为纯文档类问题)”)
else:
print(f”[DEBUG] LLM 生成 SQL: {generated_sql}”)
reason = audit_sql(generated_sql)
if reason:
print(f”[WARN] SQL 审计未通过:{reason}”)
else:
sql_rows = run_sql(generated_sql)
print(f”[DEBUG] SQL 结果条数:{len(sql_rows)}”)
except Exception as e:
print(f”[WARN] NL2SQL 或执行异常:{e}”)
# 3) 让 LLM 综合“结构化结果+文档片段”作答
answer = synthesize_with_llm(q_with_time, sql_rows, doc_hits, generated_sql)
# 4) 控制台展示
print(“\n【检索Top文档】”)
for s, ch in doc_hits:
print(f” – ({s:.3f}) [{ch.doc_id}#{ch.chunk_id}] {ch.text.strip()[:80]}…”)
print(“【结构化结果示例】”, json.dumps(sql_rows[:5], ensure_ascii=False))
print(“\n【最终回答】\n” + answer + “\n” + “-” * 60 + “\n”)
运行完成的智能体,尝试以下不同问题场景,可以看到智能体的响应流程。
1)华东地区上月销售额Top 3客户
时间增强:(时间范围提示:上月=2025-11-01~2025-11-30)
NL2SQL:SELECT c.name, SUM(o.amount) AS total_sales FROM customers c JOIN orders o ON c.id = o.customer_id WHERE c.region = ‘华东’ AND o.date >= ‘2025-11-01’ AND o.date <= ‘2025-11-30’ GROUP BY c.name ORDER BY total_sales DESC LIMIT 3;
文档检索:列出检索结果,但通常无关(OK);
回答:列出客户与金额,并明确依据结构化结果。
2) 本周华东区销售额前三是谁?
时间增强:(时间范围提示:上月=2025-12-08~2025-12-14)
NL2SQL:SELECT c.name, SUM(o.amount) AS total_sales FROM customers c JOIN orders o ON c.id = o.customer_id WHERE c.region = ‘华东’ AND o.date >= ‘2025-12-08’ AND o.date <= ‘2025-12-14’ GROUP BY c.name ORDER BY total_sales DESC LIMIT 3;
文档检索:列出检索结果,但通常无关(OK);
回答:列出客户与金额,并明确依据结构化结果。
3)A100 的质保期有多久?
NL2SQL:无需参与;
文档检索命中:[product_manual.md#0];
回答:引用“[sales_playbook.md#0]”,可验证溯源。
9.小结
本文以“结构化数据 + 非结构化知识 + 相对时间增强”的闭环为主线,给出一套可直接运行的企业问答最小实现:在SQLite中创建customers/orders两张表,支持分组、聚合与时间窗口;文档侧通过分片、embedding-3向量化与L2归一化实现Top-K召回;在进入检索与NL2SQL 前,先将“本月/上周/今年”等相对时间解析为明确日期范围并回写到提示,使两条通道共享同一时间口径。SQL由大模型生成,经过本地审计后只读执行;最终把“SQL结果 + 文档片段”打包为JSON,请模型在证据约束下作答并标注引用。全链路提供调试日志(时间提示、Top-K、SQL、审计与结果),便于定位问题。生产项目可在此基础上接入FAISS/pgvector、BM25+重排、AST级审计、只读账号与行列权限、缓存与评测体系,逐步把Demo演进为稳定可靠的知识型智能体。
本文示例代码仓库:https://gitcode.com/gtyan/AgentHandBook/tree/main/05